Lec 4: 文件系统存储布局
The Design and Implementation of the 4.4BSD Operating System
BTRFS: The Linux B-Tree Filesystem, 13
F2FS: A New File System for Flash Storage,15
- 专门为闪存设计的文件系统
TABLEFS: Enhancing Metadata Efficiency in the Local File System, 13
- 把“文件系统的元数据”存进一个 KV 存储(类似数据库)里
本讲定位
前三讲已经建立了两类底层介质的完整模型:闪存固态硬盘(纯电子、随机与顺序差距小、写前必擦、有磨损)和机械磁盘(有寻道与旋转、随机比顺序慢数百倍)。文件系统正是架在这些介质之上的那层软件,它把"一堆扇区或闪存页"变成人类和应用熟悉的文件与目录。
本讲的核心问题是:文件系统在盘上应该如何摆放它的数据结构,才能在这些物理约束下又快又可靠?我们先用 OSTEP 的"非常简单的文件系统"(vsfs)打底,然后走过传统 UNIX/FFS 的布局、面向闪存的 F2FS、写时复制的 BTRFS、以及把元数据存进键值存储的 TABLEFS,看到同一个问题的四种迥异解法。
文件系统是一个纯软件,需要解决:
- 文件的元数据如何存储
- 文件数据如何组织
- 目录如何管理
- 空闲空间如何管理
理解任何文件系统都要回答两个问题:
- 盘上的数据结构是什么?,也就是说,文件系统在磁盘上使用哪些结构来组织它的数据和元数据。 VSFS使用的非常简单的结构,用块或者其他对象组成的数组;而更复杂的FS则使用更复杂的基于树的结构
- 访问方法如何把 open、read、write 等调用映射到这些结构上?
文件系统的心智模型
对于文件系统来说,你最终应该能够回答类似这样的问题:
- 磁盘上的哪些结构存储了文件系统的数据和元数据?
- 当一个进程打开文件时会发生什么?
- 在执行 read 或 write 操作时,会访问哪些磁盘结构?
- 在执行 write 时,又会修改哪些结构?
通过不断完善你的心智模型,你就能形成一种抽象层面的理解,知道系统内部究竟发生了什么,而不是只停留在理解某个具体文件系统代码的细节(当然,理解代码本身也同样有帮助)。
VSFS
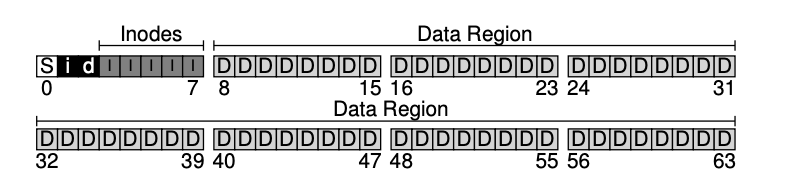
现在开始构建 vsfs 文件系统在磁盘上的整体数据结构组织方式。 首先就是把磁盘划分为一个个块(block)。简单的文件系统通常只使用一种块大小,我们在这里也采用这种方式,选择一个4KB来划分块。这些块的编号从 0 到 N−1。
在任何文件系统中,大多数空间都应该用于存储用户数据。我们把磁盘中存放用户数据的区域称为:data region(数据区),不失一般性地, 把 最后 56 个块作为数据区。
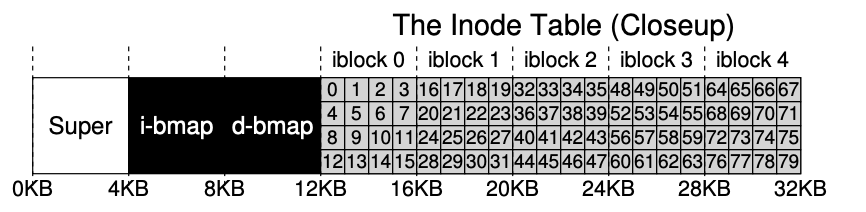
文件系统必须跟踪每一个文件的信息。为了存储这些信息,文件系统通常使用一种结构,叫做:inode(索引节点),为了存储 inode,我们需要在磁盘上专门预留一部分空间。这部分空间叫做:inode table(inode 表)inode table 本质上就是:一个 inode 数组。假设我们在这 64 个块里:用 5 个块存储 inode (在图中用 I 表示)。
接下来,如何知道哪些 inode 或数据块已经被使用?为此我们使用bitmap(位图)。位图的作用是记录:inode 是否已分配、data block 是否已分配,需要两个位图: inode位图和用户数据位图, 一个 4KB 的 bitmap 可以记录32K 个对象是否被分配。但我们的系统只有80个inode和56个数据块,虽然浪费但为了方便起见,我们还是用整整一个块来标记。
我们最后只剩下一个块还没使用,我们用来存储超级块(superblock)。superblock 记录整个文件系统的基本信息,例如:文件系统中 inode 的数量(这里是 80),数据块的数量(这里是 56),inode table 从哪里开始(这里是 block 3),文件系统类型的标识(magic number,例如 vsfs)。
当操作系统 挂载(mount) 一个文件系统时:第一步就是读取 superblock。
通过 superblock,操作系统可以:初始化文件系统参数、确定各个结构的位置,然后把这个磁盘卷挂载到文件系统树中。之后,当访问这个卷中的文件时, 系统就能准确知道去磁盘的哪里查找所需要的数据结构。
文件组织: Inode
inode的名字源自index node(索引节点),inode 被存储在一个数组中系统通过 索引 来访问某一个 inode。 inode是存储文件元数据的结构,这些元数据包括: 文件长度、权限以及文件数据块的位置,不同文件系统可能用不同名字,比如dnode、fnode,但是本质结构是一样的。
假设vsfs的indo表如下:
- inode 表大小: 20KB
- 每个inode: 256B
- 因此indo数量: 20KB / 256B = 80个inode
读取inode 32: 计算 inode 在 inode table 中的偏移,offset = 32 * sizeof(inode) = 32 * 256 = 8192,然后加上起始地址 12KB + 8192KB = 20KB,但磁盘不是按字节寻址,而是按扇区(sector)通常扇区大小为512B,所以 20KB / 512B = sector 40 ,文件系统就会读取sector 40来获取这个inode。
inode里面存储什么?答,几乎包含关于文件的所有信息:
inode 中几乎包含 关于文件的所有信息:
例如:
- 文件类型
- 文件大小
- 文件数据块位置
- 权限
- 时间信息
这些信息统称为:metadata(元数据)
inode如何指向数据块?答:最简单的方法——使用 直接寻址指针(direct pointer)。
如果文件很大怎么办?因为 inode 中的指针数量是有限的。答:多级索引(Multi-Level Index),引入间接寻址。
inode
├─ direct pointer → data block
├─ direct pointer → data block
├─ indirect pointer → block of pointers
├─ data block
├─ data block
└─ data block如果 inode 有12个直接寻址指针,一个间接寻址指针,假设指针大小为4B,则最大文件大小:(12 + 4KB / 4B ) × 4KB = 4144KB
许多文件系统使用这种方法,例如:
- ext2
- ext3
- WAFL
- 早期 Unix FS
另一种设计不是使用大量指针,而是使用:extent,例如,start block = 100, length = 50;表示block 100 ~ 150。 优点是metadata 少、连续存储效率高;缺点不够灵活、有外部碎片问题。
现代文件系统:
- XFS
- Linux ext4 都适用extent
为什么 inode 是这种“不平衡树”结构?因为研究发现一个重要事实:绝大多数文件都很小
典型统计:
| 现象 | 结果 |
|---|---|
| 最常见文件大小 | ≈ 2KB |
| 平均文件大小 | ≈ 200KB |
| 大部分空间 | 被少数大文件占用 |
| 文件系统平均文件数 | ≈100K |
| 磁盘平均利用率 | ≈50% |
| 目录大小 | 大多数 <20 个文件 |
因此设计策略是优化小文件, 小文件不需要额外的indirect block
目录组织
在 vsfs(以及许多文件系统)中,目录的结构非常简单,一个目录本质上就是一组 (文件名, inode号)的列表,也就是说,目录的数据块中存放的是很多条记录,每条记录包含 文件名 + inode number
论文阅读: F2FS
论文阅读: BTRFS
BTRFS 是开源的文件系统,自 2007 年诞生以来一直在持续发展。
它的主要特性包括:
- 对所有元数据和数据维护 CRC 校验
- 高效的可写快照和克隆,作为一等公民支持
- 多设备支持
- 在线扩容和碎片整理
- 数据压缩
- 对小文件的高效存储
- 针对 SSD 的优化以及 TRIM 支持
其设计目标是:能够很好地适应各种不同类型的工作负载,并且在文件系统“老化”后仍然保持良好的性能。BTRFS 的目标是成为 Linux 的默认文件系统。在磁盘布局上,该文件系统由一片 B 树森林 组成,并采用写时复制(Copy-On-Write, COW)作为更新机制。磁盘块以 extent(区间块) 的方式进行管理,并通过校验和来保证数据完整性,同时使用引用计数来进行空间回收。
文件系统的性能依赖于是否能够获得长且连续的区间块。然而,随着系统使用时间的增长,磁盘空间会越来越碎片化,因此需要进行在线碎片整理(defragmentation)。由于存在快照(snapshot),一个磁盘 extent 可能被多个文件系统卷同时引用。这使得碎片整理变得困难,原因有两点:
- 只有在更新所有指向该 extent 的引用之后,才能移动该 extent
- 希望在所有快照中都保持文件的连续性
为了充分利用现代 CPU,高并发性非常重要。然而,在写时复制机制下,实现高并发是困难的,因为每一次更新都会逐层向上传播,一直到文件系统的根节点。
在Linux上,有三种流行的文件系统,Ext4、XFS、BTRFS。在COW文件系统中,两个重要的现代系统是是ZFS和WAFL,我们将”覆盖写(overwrite)文件系统“定义为:直接在原位置更新文件的数据结构。这是目前最主流的设计方式。