Lec 1 概述 & Flash SSD操作 I
阅读资料
- Amvrosiadis, George and Ganger, Greg 18-746/15-746 Course Syllabus
- Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau Operating Systems: Three Easy Pieces
- Agrawal, Nitin and Prabhakaran, Vijayan and Wobber, Ted and Davis, John D. and Manasse, Mark and Panigrahy, Rina Design Tradeoffs for SSD Performance In USENIX 2008 Annual Technical Conference, 2008, pages 57--70
- Hennessy, John L. and Patterson, David A. Computer Architecture: A Quantitative Approach
- Mor Harchol-Balter Probability Refresher
课程定位
SSD介绍
我们基于三星 K9XXG08UXM 系列 NAND 闪存芯片为例,这是一个单层(SLC)闪存,多层单元(MLC)闪存虽然成本更低,但是性能和寿命不如SLC。图一展示了闪存封装的结构示意图。
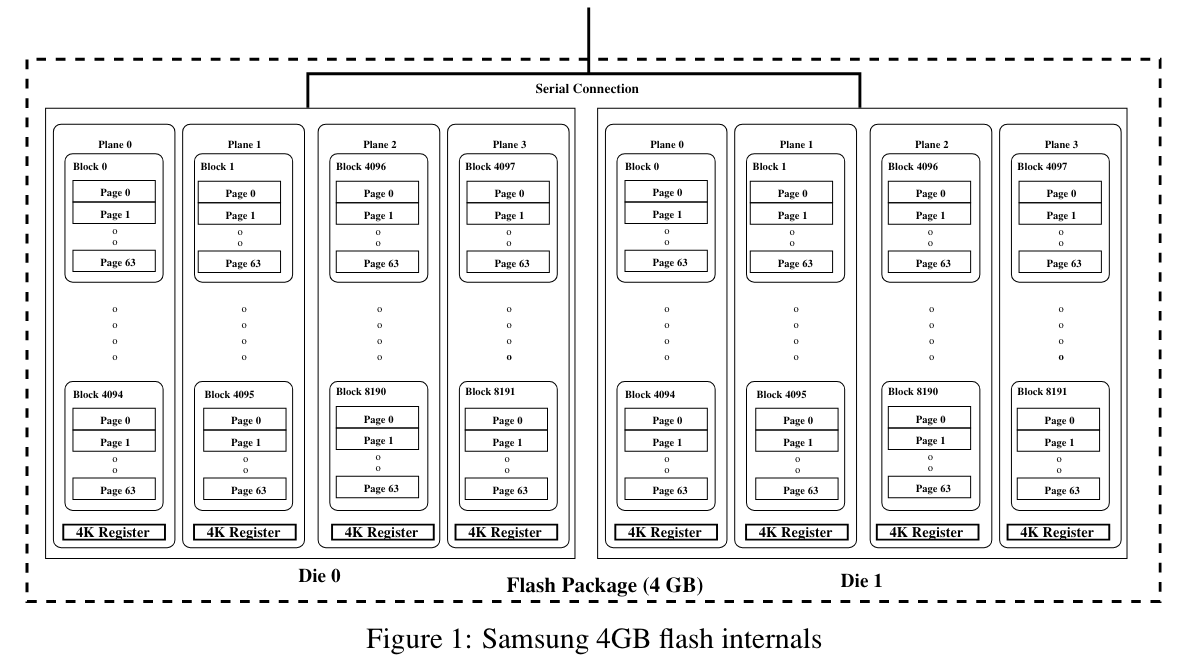
图 1 展示了一个闪存封装的结构示意图。一个闪存封装由一个或多个 die(也称芯片)组成。我们讨论的是一个 4GB 的闪存封装,它由两个 2GB 的 die 组成,共享一个 8 位宽的串行 I/O 总线以及若干公共控制信号。这两个 die 具有独立的片选(chip enable)和就绪/忙碌(ready/busy)信号。因此,当一个 die 正在执行某个操作时,另一个 die 可以接收命令和数据。该封装还支持两个 die 之间的交错操作(interleaving)。每个 die 包含 8192 个块,这些块分布在 4 个 plane 中,每个 plane 有 2048 个块。每个 die 可以独立运行,每次操作可以涉及一个或两个 plane。双 plane 命令可以在 plane 对 0 & 1 或 2 & 3 上执行,但不能跨其他组合。每个块包含 64 个 4KB 的页面。除数据外,每个页面还包含一个 128 字节的区域,用于存储元数据(如标识信息和错误检测信息)。
基本特性
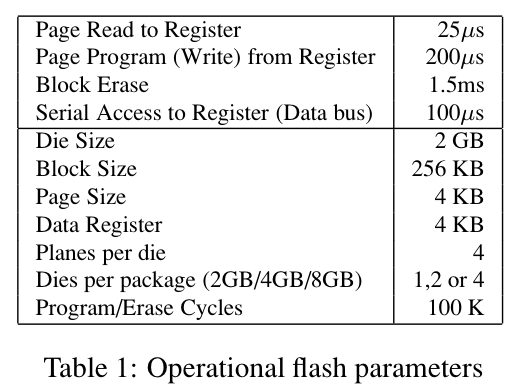
表 1 给出了三星 4GB 闪存的操作属性。数据读取以页面为单位。一次典型的读取操作需要 25 微秒将页面从闪存介质读入 4KB 的数据寄存器,然后再通过数据总线将其移出。串行线的传输速率为每字节 25 纳秒,即每页大约需要 100 微秒完成数据输出。在闪存中,一个块在被重新写入前必须先擦除。一次擦除操作需要 1.5 毫秒,这远比读或写操作昂贵。此外,每个块的擦除次数是有限的。当前一代闪存的擦除上限约为 10 万次,因此必须谨慎管理块的重复使用。写入(编程)同样以页面为单位进行:先将数据通过串行接口写入数据寄存器(100 微秒),然后再写入闪存单元(200 微秒)。在一个块内部,页面必须按照地址从低到高顺序写入。
该芯片还提供一种专用的 copyback 编程操作,可以在芯片内部将一个页面复制到另一个页面,从而避免通过串行总线传输数据到外部缓冲区,提高性能。
带宽与交错
闪存封装接收命令和传输数据所使用的串行接口,是 SSD 性能的主要瓶颈。三星芯片大约需要 100 微秒将一个 4KB 页面从片上寄存器传输到片外控制器,而从 NAND 单元读入寄存器只需 25 微秒。如果这两个操作串行执行,一个闪存封装每秒只能完成 8000 次页面读取(约 32MB/s)。如果在一个 die 内部使用交错机制,则单个芯片的最大读取带宽可以提升至每秒 10000 次(约 40MB/s)。
写操作上, 每页同样需要100微秒的串行传输时间,但编程时间为200微秒。我们可以在两个die上交错执行三种操作,是读写速度接近串口接口的极限。当操作延迟大于串行访问延迟时,交错可以带来显著的性能提升。例如,耗时较长的擦除命令可以与其他命令并行执行。再如,在两个封装之间进行完全交错的页面复制时,尽管单次写入需要 200 微秒,但整体速度可以接近每页 100 微秒。
在这种情况下,4 个源 plane 和 4 个目标 plane 可以高效复制页面,同时避免在同一个 plane 对上执行冲突操作,并充分利用连接到两个闪存 die 的串行总线引脚。一旦流水线填满,每 100 微秒即可完成一次写入。
不过,即便闪存架构支持交错,也存在严格限制。例如,同一 flash plane 上的操作不能交错执行。这意味着同一封装内的交错操作,最好用于一组精心安排的相关操作,例如多页读取或写入。
我们测试的三星芯片还支持一种快速内部 copy-back 操作,可在芯片内部将数据复制到同一 plane 内的另一个块,而无需经过串行引脚。这种优化有其代价:数据只能在同一个 flash plane(2048 个块范围内)复制。
两个这样的复制操作可以在不同 plane 上交错执行,其性能类似于前述完全交错的跨封装复制,但无需占用串行引脚资源。
逻辑组成
所有基于 NAND 的 SSD 都是由多个闪存封装(flash packages)组成的阵列构建而成,图3展示了通用的SSD模块框图。
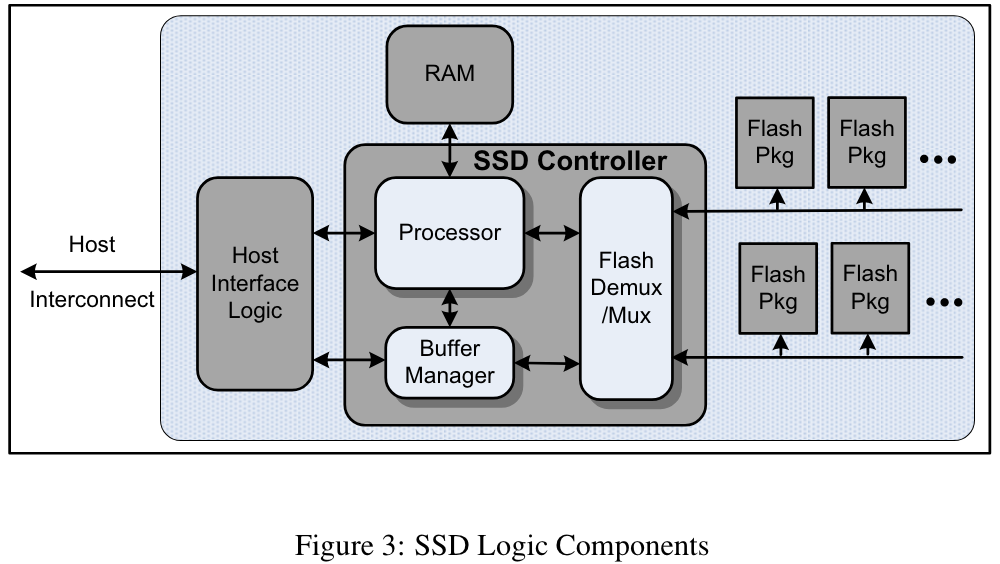
每个 SSD 都必须包含主机接口逻辑(Host Interface Logic),用于支持某种物理主机接口连接(如 USB、Fiber Channel、PCI Express、SATA),以及逻辑磁盘仿真功能,例如通过闪存转换层(Flash Translation Layer,FTL)机制,使 SSD 能够模拟传统机械硬盘的行为。主机互连带宽往往是整个设备性能的关键约束因素,因此必须与闪存阵列所能提供的读写性能相匹配。
在主要数据通路上,内部缓冲管理器(buffer manager)用于保存待处理和已完成的请求。一个多路复用器(Flash Demux/Mux)负责向闪存封装发出命令,并通过串行连接传输数据。该多路复用器还可以包含额外的逻辑,例如用于缓存命令和数据。此外,还需要一个处理引擎(processing engine)来管理请求流,以及完成从磁盘逻辑块地址(logical block address, LBA)到物理闪存位置的映射。
处理器、缓冲管理器和多路复用器通常通过独立组件(如 ASIC 或 FPGA)实现,这些逻辑单元之间的数据流速度非常快。处理器及其相关 RAM 可能集成在同一芯片中(例如简单的 USB 闪存盘),也可能采用独立结构(用于具有更复杂处理和更大内存需求的设计)。
闪存封装通常提供一个 8 位宽的串行数据接口,以及数量相当的控制引脚。例如,一个 32GB 的 SSD,如果使用 8 个三星闪存芯片,仅闪存控制器一侧就需要为这些闪存组件提供 136 个引脚。在这样的配置下,闪存控制器与闪存封装之间或许可以实现完全互连,但对于更大规模的配置,这种方式很可能不再可行。
逻辑块映射
NAND 闪存的物理特性决定了它无法像机械硬盘那样进行原地写入(in-place update)。写操作应尽可能顺序执行,类似于日志结构。由于每一次对单个逻辑磁盘块地址(LBA)的写入,都对应写入到一个不同的物理闪存页,因此即便是最简单的 SSD,也必须维护某种逻辑块地址到物理闪存位置之间的映射关系。我们假设逻辑块映射表保存在易失性内存中,并在系统启动时从稳定存储中重建。
为了讨论逻辑块映射,我们引入“分配池”(allocation pool)这一抽象概念,用来思考 SSD 如何分配闪存块以响应写请求。在处理写请求时,每一个目标逻辑页(4KB)都会从一个预先设定的闪存内存池中进行分配。一个分配池的范围可以小至一个闪存 plane,也可以大至多个闪存封装。
在考虑分配池特性时,可以从以下几个变量来分析:
- 静态映射:每个LBA的一部分构成对某个特定分配池的固定映射
- 动态映射:LBA 中不属于静态部分的那部分,将作为在分配池内部查找映射关系的键。
- 逻辑页大小:一个映射条目所对应的数据单位大小,可以大至一个闪存块(例如 256KB),也可以小至四分之一页(1KB)
- 页跨度: 一个逻辑页可能横跨不同闪存封装中的相关页面,从而使页面的不同部分可以并行访问
这些变量受到三个约束条件的限制:
- 负载均衡: 理想情况下,I/O 操作应在各个分配池之间均匀分布。
- 并行访问: LBA 到物理地址的分配方式,应尽量不影响这些 LBA 的并行访问能力。例如,如果 LBA0 到 LBAn 经常被同时访问,它们就不应存储在一个必须串行访问的组件上
- 块擦除: 闪存页在被重新写入前必须先擦除,而擦除只能按固定大小的连续页块进行。
定义分配池的这些变量,与上述约束之间存在权衡关系。例如,
- 如果 LBA 空间中有很大一部分采用静态映射,那么系统在负载均衡方面的灵活性就会很小。
- 如果一段连续的 LBA 被映射到同一个物理芯片(die)上,那么在进行大块顺序访问时,性能会受到影响。
- 如果逻辑页大小较小,那么在选择擦除候选块时,需要做更多工作来排除其中仍然有效的页面。
- 如果逻辑页大小(且跨度为 1)等于块大小,那么擦除操作会变得简单,因为写入单位与擦除单位一致;但所有小于逻辑页大小的写操作都会触发读-修改-写(read-modify-write)过程,需要处理逻辑页中未被修改的部分。
在 RAID 系统中,通常会将逻辑上连续的数据块(例如 64KB 或更大)条带化分布到多个物理磁盘上。在这里,我们采用更细粒度的条带化方式,将逻辑页(4KB)分布到多个闪存 die 或封装上。这种做法既可以分散负载,也能确保连续页面被放置在不同的封装上,从而实现并行访问。
擦除
在 Birrell 等人提出的设计基础上进一步展开,我们将闪存块(flash block)作为分配池中的自然分配单位。在任意时刻,一个分配池可以拥有一个或多个“活动块”(active blocks),用于存放新到来的写请求。
了持续获得新的活动块,需要一个垃圾回收器(garbage collector)来枚举那些已经使用过、需要被擦除并重新利用的块。
如果逻辑页的粒度小于闪存块的大小,那么在块被擦除之前必须进行清理操作。清理过程可以概括如下:
当一个页面写入完成后,之前映射到的页面位置就会被“取代”(superseded),因为其中的数据已经过时。
在回收某个候选块时,在擦除该块之前,所有仍然有效(未被取代)的页面都必须被写入到其他位置。
在最坏情况下,如果被取代的页面均匀分布在所有块中,那么每进行一次新的数据写入,就需要执行 N−1 次清理写操作(其中 N 是每个块中的页数)。
当然,大多数实际工作负载会产生写入活动的局部聚集,这会导致当数据被覆盖时,一个块中出现多个已被取代的页面。
我们引入“清理效率”(cleaning efficiency)这一概念,用于量化在块清理过程中,被取代页面数量与总页面数量之间的比例。
虽然可以使用多种算法来选择需要回收的候选块,但始终应当尽量提高清理效率。
值得注意的是,为了提高顺序地址的并行访问能力而使用的条带化(striping),实际上会削弱被取代页面的聚集性。
对于每个分配池,我们维护一个空闲块列表(free block list),其中存放被回收的块。在本节和下一节中,我们假设采用一种纯粹的贪心策略:根据潜在的清理效率来选择需要回收的块。
如第 2 节所述,NAND 闪存中的每个块只能被擦除有限次数。因此,在选择回收候选块时,应尽量使所有块的“老化程度”保持均衡。这一性质通过所谓的“磨损均衡”(wear-leveling)机制来实现。
在第 5 节中,我们将讨论清理候选块的选择如何与磨损均衡直接相关,并提出一种改进的贪心算法。
在模拟传统磁盘接口的 SSD 中,并不存在“空闲磁盘扇区”的抽象。因此,从其对外公布的容量来看,SSD 始终处于“满”的状态。
为了使清理机制能够正常工作,系统必须保留足够的备用块(这些块不计入对外容量),以便写操作和清理操作能够继续进行,同时也能在块失效时进行替换。
SSD 通常会预留相当比例的额外容量(over-provisioning),以减少前台操作中对清理块的需求。此外,延迟块清理也可能在非随机工作负载下产生更好的过时页面聚集效果。
在上一小节中,我们假设每个 LBA 都被静态映射到一个特定的分配池。不过,清理操作实际上可以在更细粒度上进行。
这样做的一个原因,是为了利用闪存架构中的低层效率,例如第 2.2 节提到的内部 copy-back 操作,这种操作只在同一个 plane 内移动页面时才适用。
由于单个闪存 plane(包含 2048 个块)对于负载分布来说是一个很小的分配池,我们希望从更大的池中进行分配。但如果为每个 plane 维护一个活动块和清理状态,那么在同一个 plane 内执行清理操作的概率就会很高。
人们可能会把块清理看作类似于日志结构文件系统(Log-Structured File System,LFS)中的日志清理。实际上,两者确实存在一些相似之处。
不过,除了我们这里建模的是块存储(block store)而不是文件系统这一明显差别之外,一个严格按照磁盘顺序进行写入和清理的日志结构存储,无法通过选择候选块来提高清理效率。
而且,就像 LFS 类型的文件系统一样,很容易出现这样的工作负载组合:所有可回收空间都位于日志清理指针很远的位置。
例如,如果反复写入同一组块,那么清理指针必须遍历整个磁盘内容一轮,才能到达日志末尾附近的空闲空间。
并且,与日志结构文件系统不同,这里的磁盘始终处于“满”的状态,这意味着系统始终承受着最大的清理压力。