Lec 10 分布式FS & NAS接口
- The Design and Implementation of the 4.4BSD Operating System, CHAPTER 9
- Scale and Performance in a Distributed File System, 1988
- Operating Systems: Three Easy Pieces, CH48——Distributed System
- Operating Systems: Three Easy Pieces, CH49——NFS
- Operating Systems: Three Easy Pieces, CH50——AFS
- RFC 1813 —— NFS Version 3 Protocol Specification
一、本讲定位
前面的讲次都在讨论单机上的存储:一台机器的磁盘或固态硬盘上怎么放文件系统、怎么做缓存、怎么保证完整性。本讲跳出单机,进入分布式文件系统——多台客户端通过网络访问一台或少数几台服务器上的文件。这是网络附加存储(Network-Attached Storage, NAS)的核心技术基础。我们重点比较两个开创性系统:Sun 的网络文件系统(Network File System, NFS)和 CMU 的安德鲁文件系统(Andrew File System, AFS),它们在协议设计上做了截然相反的选择,各自带来不同的性能、可扩展性和一致性特征。
二、分布式系统基础:通信、故障与远程过程调用
核心挑战是故障(failure)。单机上磁盘坏了或进程崩了已经够烦,分布式系统里机器、磁盘、网络、软件都可能在任何时候失败,而且故障不可避免——数据中心里几千台机器同时运行,故障是常态而非例外。但这也是机会:把机器集合起来,可以构建一个看起来几乎从不宕机的系统,尽管其组成部分经常失败。
通信本质上不可靠。比特翻转、链路故障、路由器缓冲区溢出都会导致丢包。网络层有两种应对思路:不可靠通信层(如 UDP)让应用自己处理丢包,适合那些知道如何应对的场景——这是端到端论证(end-to-end argument)的体现;可靠通信层(如 TCP)在底层用确认(acknowledgment, ACK)、超时重传(timeout/retry)和序列号(sequence counter)保证消息恰好送达一次(正常情况下)或至多一次(故障情况下)。
远程过程调用(Remote Procedure Call, RPC)是构建分布式系统最主流的通信抽象。它的目标是让远程调用看起来和本地函数调用一样简单。RPC 系统由两部分构成:存根生成器(stub generator)自动生成客户端和服务器的序列化/反序列化代码,把函数参数打包成消息、把消息解包成返回值;运行时库(run-time library)处理命名(怎么找到服务器)、传输协议选择(TCP 还是 UDP)、超时重试、字节序转换等底层细节。很多 RPC 系统建在 UDP 之上而非 TCP,以避免 TCP 的双重确认开销——请求本身的回复就充当了确认,无需额外的传输层 ACK。
最后,安全性也是必须考虑的问题。当连接到远程站点时,一个核心问题是:如何确保远程通信方确实是它所声称的那个实体?此外,还需要确保第三方无法监听通信内容、以及篡改通信数据。
通信基础
现代网络的一个核心原则是:通信在本质上是不可靠的。不过,更根本的一种数据包丢失原因是:网络设备内部缓冲区不足。
具体来说,即使我们能够保证:
- 所有网络链路都正常工作
- 系统中的所有组件(交换机、路由器、主机)都在运行
数据包仍然可能丢失。为了处理这个数据包,它必须先被放入路由器的某个内存缓冲区。如果同时到达很多数据包,路由器的内存可能无法容纳所有数据包。在这种情况下,路由器唯一能做的就是:丢弃其中的一些数据包。
不可靠通信层
一种简单的办法是:不去处理它。因为有些应用程序本身就能够处理数据包丢失,因此有时候让它们直接使用一个基本的、不可靠的消息层进行通信是有意义的。这就是所谓的 端到端原则(end-to-end argument) 的一个例子
udp.h
#ifndef __UDP_H__
#define __UDP_H__
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define BUFFER_SIZE 1024
int UDP_Open(int port);
int UDP_FillSockAddr(struct sockaddr_in *addr,
char *hostname,
int port);
int UDP_Write(int sd,
struct sockaddr_in *addr,
char *buffer,
int n);
int UDP_Read(int sd,
struct sockaddr_in *addr,
char *buffer,
int n);
#endifudp.c
#include "udp.h"
#include <string.h>
#include <unistd.h>
#include <netdb.h>
int UDP_Open(int port) {
int sd;
if ((sd = socket(AF_INET, SOCK_DGRAM, 0)) == -1)
return -1;
struct sockaddr_in myaddr;
bzero(&myaddr, sizeof(myaddr));
myaddr.sin_family = AF_INET;
myaddr.sin_port = htons(port);
myaddr.sin_addr.s_addr = INADDR_ANY;
if (bind(sd, (struct sockaddr *) &myaddr, sizeof(myaddr)) == -1) {
close(sd);
return -1;
}
return sd;
}
int UDP_FillSockAddr(struct sockaddr_in *addr, char *hostname, int port) {
bzero(addr, sizeof(struct sockaddr_in));
addr->sin_family = AF_INET; // host byte order
addr->sin_port = htons(port); // network byte order
struct in_addr *in_addr;
struct hostent *host_entry;
if ((host_entry = gethostbyname(hostname)) == NULL)
return -1;
in_addr = (struct in_addr *) host_entry->h_addr;
addr->sin_addr = *in_addr;
return 0;
}
int UDP_Write(int sd, struct sockaddr_in *addr, char *buffer, int n) {
int addr_len = sizeof(struct sockaddr_in);
return sendto(sd, buffer, n, 0,
(struct sockaddr *) addr, addr_len);
}
int UDP_Read(int sd, struct sockaddr_in *addr, char *buffer, int n) {
int len = sizeof(struct sockaddr_in);
return recvfrom(sd, buffer, n, 0,
(struct sockaddr *) addr,
(socklen_t *) &len);
}client.c
#include "udp.h"
#include <stdio.h>
int main(int argc, char *argv[]) {
int sd = UDP_Open(20000);
struct sockaddr_in addrSnd, addrRcv;
int rc = UDP_FillSockAddr(&addrSnd, "cs.wisc.edu", 10000);
char message[BUFFER_SIZE];
sprintf(message, "hello world");
rc = UDP_Write(sd, &addrSnd, message, BUFFER_SIZE);
if (rc > 0)
rc = UDP_Read(sd, &addrRcv, message, BUFFER_SIZE);
return 0;
}server.c
#include "udp.h"
#include <stdio.h>
#include <assert.h>
int main(int argc, char *argv[]) {
int sd = UDP_Open(10000);
assert(sd > -1);
while (1) {
struct sockaddr_in addr;
char message[BUFFER_SIZE];
int rc = UDP_Read(sd, &addr, message, BUFFER_SIZE);
if (rc > 0) {
char reply[BUFFER_SIZE];
sprintf(reply, "goodbye world");
rc = UDP_Write(sd, &addr, reply, BUFFER_SIZE);
}
}
return 0;
}可靠通信层
为了构建一个可靠的通信层,我们需要一些新的机制和技术来处理数据包丢失的问题。让我们考虑一个简单的例子:客户端通过一个不可靠的连接向服务器发送消息。
我们必须回答的第一个问题是:发送方如何知道接收方确实收到了消息?我们将使用一种称为 确认(acknowledgment,简称 ack) 的技术。其思想很简单:发送方发送一条消息给接收方;接收方随后发送一条简短的消息回来,确认它已经收到了该消息。图 48.3 描述了这一过程。
当发送方收到这条确认消息时,它就可以确信接收方确实收到了原始消息。但如果发送方没有收到确认消息,它应该怎么办?为了处理这种情况,我们需要另一种机制,称为 超时(timeout)。当发送方发送一条消息时,它会设置一个定时器,在一段时间后触发。如果在这段时间内没有收到确认消息,发送方就认为该消息已经丢失。随后发送方会 重新发送(retry) 该消息,希望这次能够成功到达。为了实现这一机制,发送方必须保存一份消息副本,以便需要时重新发送。超时(timeout)和重试(retry) 的组合常被称为 timeout/retry 机制
不幸的是,仅靠 timeout/retry 机制还不够。图 48.5 展示了一种可能导致问题的丢包情况。在这个例子中,丢失的不是原始消息,而是 确认消息(ack)。从发送方的角度来看,情况与之前一样:没有收到确认,因此需要超时并重试。然而从接收方的角度来看,情况却不同:同一条消息被接收了两次。
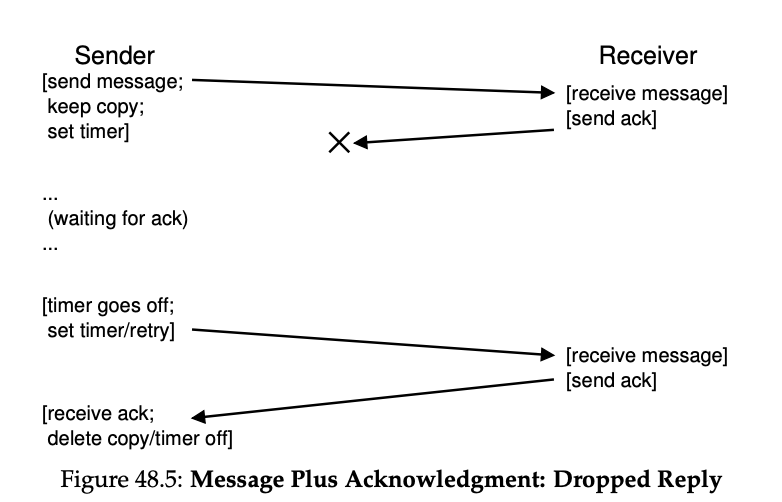
在某些情况下这也许可以接受,但通常并不行。想象一下,如果你在下载文件时,某些数据包被重复插入到文件中会发生什么。因此,在构建可靠消息层时,我们通常还希望保证 每条消息只被接收一次(exactly-once semantics)。为了让接收方能够检测重复消息,发送方必须以某种方式 唯一标识每条消息,而接收方需要记录自己是否已经见过该消息。当接收方检测到重复消息时,它仍然发送确认(ack),但 不会把该消息交给上层应用程序。这样发送方可以收到确认,但应用层不会收到重复消息,从而保证“只接收一次”的语义。
检测重复消息的方法有很多。例如,发送方可以为每条消息生成一个唯一 ID,接收方记录所有已经见过的 ID。虽然这种方法可行,但代价很高,因为它需要 无限增长的内存 来保存所有 ID。一种更简单且只需要很少内存的方法是使用 序列计数器(sequence counter)。在这种机制中,发送方和接收方会约定一个初始值(例如 1),双方都维护一个计数器。每当发送一条消息时,发送方会把当前计数器的值一起发送出去。这个值 N 就作为该消息的 ID。消息发送后,发送方将计数器增加到 N + 1。
接收方使用自己的计数器作为 期望接收的消息 ID。如果接收到的消息 ID(N)与接收方当前的计数器值(也是 N)相同,那么接收方就确认该消息,并把它传递给应用程序。这时接收方认为这是第一次收到该消息。然后接收方将计数器增加到 N + 1,等待下一条消息。如果确认消息丢失了,发送方会超时并重新发送消息 N。这一次接收方的计数器已经是 N + 1,因此接收方知道这条消息已经接收过了。于是它 再次发送确认消息,但不会把该消息交给应用程序。通过这种简单的方法,序列计数器就可以避免重复消息。
最常用的可靠通信层被称为 TCP/IP,通常简称 TCP。TCP 的机制比我们这里介绍的要复杂得多,包括处理网络拥塞的机制、多条未完成请求的管理,以及大量其他优化。
通信抽象
在拥有一个基本的消息通信层之后,我们现在可以思考本章的下一个问题:在构建分布式系统时,我们应该使用什么样的通信抽象?
DSM
多年来,系统研究领域提出了多种方法。其中一类研究尝试将 操作系统中的抽象扩展到分布式环境中。例如,分布式共享内存(Distributed Shared Memory,DSM) 系统允许运行在不同机器上的进程共享一个巨大的虚拟地址空间。这种抽象使得分布式计算看起来就像一个 多线程程序;唯一的区别是,这些“线程”运行在不同的机器上,而不是运行在同一台机器的不同处理器上。
大多数 DSM 系统的实现方式依赖于操作系统的 虚拟内存系统。当某台机器访问一个内存页时,可能发生两种情况:第一种情况(最理想的情况): 该页已经在本地机器上,因此可以很快读取数据;第二种情况:该页当前位于另一台机器上。此时会发生 页错误(page fault)。页错误处理程序会向另一台机器发送消息,请求获取该页,将其安装到请求进程的页表中,然后继续执行程序。
然而,由于多种原因,这种方法如今并没有被广泛使用。最大的一个问题是 故障处理(failure handling)。例如,如果某一台机器发生故障,那么存储在该机器上的内存页会发生什么?如果分布式计算中的数据结构分布在整个地址空间中,那么其中一部分数据结构就会突然变得不可访问。另一个问题是 性能问题。在编写程序时,人们通常假设 内存访问是非常廉价的。然而在 DSM 系统中,有些内存访问确实很快,有些却很慢(需要远程访问的)。虽然在这一领域进行了大量研究,但在实际系统中产生的影响并不大。如今,几乎没有人使用 DSM 来构建可靠的分布式系统。
Message Passing
第二类后来成为主流,就是显式消息通信,例如RPC、HTTP、gRPC、Actor
远程过程调用
虽然操作系统层面的抽象在构建分布式系统时效果并不好,但编程语言层面的抽象却更加合理。其中最主流的一种抽象是 远程过程调用。RPC 的核心目标非常简单:让在远程机器上执行代码的过程,看起来就像调用本地函数一样简单。因此,对于客户端来说,它只是调用一个函数;过一段时间后,结果就返回了。服务器只需要定义一些它希望对外提供的函数。其余复杂的工作都由 RPC 系统处理
RPC 系统通常由两部分组成:
- Stub 生成器(stub generator,也叫协议编译器)
- 运行时库(run-time library)
下面分别介绍这两部分。
Stub生成器
Stub 生成器的工作很简单: 自动生成代码来打包函数参数和返回值,从而减少程序员手写消息打包代码的麻烦。
这样做有几个好处:避免手写代码时常见的错误、编译器可以自动优化、提高性能。
Stub 编译器的输入通常是 服务器希望提供给客户端调用的接口定义, Stub 生成器会根据这个接口生成不同的代码。。例如:
interface {
int func1(int arg1);
int func2(int arg1, int arg2);
};对于客户端,会生成 client stub, 客户端程序只需要链接这个stub,然后想普通函数 一样调用它,例如func1(x),实际上客户端 stub 在内部会执行以下步骤:
- 创建消息缓冲区,通常是连续的字节数组
- 打包参数,将函数标志符和参数写入消息缓冲区,这个过程叫做marshaling(参数封装)、serialization(序列化)
- 发送消息到RPC服务器,通信细节有RPC运行时库处理
- 等待服务器回复,因为函数调用通常是同步的
- 解包返回值,从回复消息中提取返回值。这个过程称为 unmarshaling、deserialization(反序列化)
- 将结果返回给调用者。
对于服务器端也会生成相应代码,执行步骤如下:
- 解包消息,提取函数标志符和参数
- 调用真实函数,RPC运行时根据函数ID调用对应函数
- 打包返回结果,将返回值序列化到回复消息中
- 发送回复,把结果发送回客户端。
Stub编译器还需要处理复杂参数,例如write(fd, buffer, size),参数包括文件描述符、缓冲区指针,数据大小。如果RPC接口中出现指针,系统需要知道指针指向多少数据,需要序列化哪些内容。通常有两种解决方法,1是使用预定义类型(例如buffer类型),2是在数据结构中添加注解,让编译器知道如何序列化。
服务器的并发模型
最简单的服务器结构,一次只能处理一个
while(true)
接收请求
处理请求这种方式效率很低,大多数RPC服务器采用并发模型。常见的是 线程池(thread pool),服务器启动时创建固定数量线程。工作流程:
- 主线程接收请求
- 将请求分发给 worker 线程
- worker 线程执行 RPC
- 发送回复
优点:
- 可以并发执行 RPC
- 提高 CPU 利用率
缺点:
- 编程复杂度增加
- 需要锁和同步机制
运行时库
RPC 系统的大部分复杂工作都在运行时库中完成,例如性能优化、可靠性处理。下面介绍几个关键问题。
服务定位(Naming)
客户端需要知道服务器在哪,最简单的方法是使用主机名、IP地址、端口号。更复杂的系统会用DNS、服务器发现系统。
UDP还是TCP
很多RPC系统会用UDP,其优点是消息更少、延迟更低;缺点是不可靠;比如自己实现超时充实、ACK和序列号机制。通过序列号可以实现,每个RPC恰好执行一次。
大消息处理
有些 RPC 参数可能非常大,超过一个网络包大小。解决方法,1是网络协议负责分片和重组,2是RPC运行时自己实现分片
字节序问题
RPC需要统一格式
同步RPC与异步RPC
异步RPC流程:
- 客户端发送 RPC 请求
- 立即返回
- 客户端继续做其他工作
之后再查询 RPC 结果。
端到端原则认为:某些功能只有在系统的最高层(应用层)才能真正正确实现。例如 可靠文件传输。即使网络层保证可靠:数据仍可能:在发送端内存损坏、在接收端写入磁盘时损坏。因此真正的可靠性检查必须在应用层完成。例如:传输完成后,计算文件 checksum,比较发送端和接收端,只有这样才能保证真正可靠。
三、NFS:无状态协议设计
Sun 的网络文件系统是最早也最成功的分布式文件系统之一。Sun 采取了一个不寻常的策略:它开发的不是一个封闭产品,而是一个开放协议(open protocol),精确定义客户端和服务器之间的消息格式。任何厂商都可以实现自己的 NFS 服务器并在市场上竞争,同时保持互操作性。这种开放市场策略极大推动了 NFS 的普及。

3.1 设计核心: 无状态
NFSv2 的首要设计目标是服务器崩溃后的快速恢复。实现方式是让协议无状态:服务器不追踪任何客户端的状态——不知道哪个客户端缓存了哪些块,不知道哪些文件被打开了,不知道当前文件指针在哪里。每个协议请求都包含完成该请求所需的全部信息。
对比有状态协议的问题。假设客户端发 open 给服务器,服务器返回一个文件描述符,后续 read 用这个描述符。如果服务器在第一次 read 后崩溃重启,它丢失了"描述符对应哪个文件"的信息——这个信息是临时的、在内存里的。要恢复就需要复杂的恢复协议。更糟的是,服务器还要处理客户端崩溃——客户端打开文件后崩溃了,永远不会发 close,服务器必须检测客户端崩溃才能释放资源。无状态协议彻底回避了这些问题。
3.2 NFSv2 协议
协议的关键构件是文件句柄(file handle),由卷标识符(volume identifier,指明哪个文件系统)、索引节点号(inode number,指明哪个文件)和世代号(generation number,防止索引节点号复用后误访问新文件)三部分组成。核心协议消息包括:
- LOOKUP:给一个目录文件句柄和一个文件名,返回该文件的句柄和属性。客户端用它逐级遍历路径——先用根目录句柄查
foo,得到foo的句柄,再用它查bar,以此类推。 - READ:给文件句柄、偏移量和字节数,服务器读取并返回数据和最新属性。
- WRITE:给文件句柄、偏移量、字节数和数据,服务器写入并返回属性。
- GETATTR:给文件句柄,返回文件属性(包括最后修改时间),后面会看到它在缓存一致性里的关键角色。
- CREATE / REMOVE / MKDIR / RMDIR / READDIR 等。
一次完整的文件读取流程:应用调 open("/foo/bar"),客户端文件系统发两次 LOOKUP(先查 foo、再查 bar)得到 bar 的文件句柄,在本地打开文件表里分配描述符、记录句柄和当前偏移量 0。应用调 read,客户端用记录的句柄和偏移量发 READ 给服务器,收到数据后更新偏移量。close 时只清理本地结构,不需要和服务器通信。注意所有状态都在客户端维护,服务器完全无状态。