Lec 8 分支预测
本讲主线
深流水处理器里,分支惩罚严重限制性能。本讲沿"方向预测"与"目标预测"两条线展开:从静态预测 → 1-bit/2-bit BHT → 利用历史相关性的两级预测 → 锦标赛/TAGE;再用 BTB + 返回栈解决"目标地址何时可知"。
一、控制流惩罚
取指与分支解析之间现代处理器可能有 >10 段。预测错误时损失的工作量 ≈ 流水深度 × 流水宽度。而 SPEC CPU 2017 中分支约占 11–19%,分支间平均运行长度仅 5–10 条指令——惩罚频繁发生。
| 指令 | "是否 taken"何时知 | "目标"何时知 |
|---|---|---|
| JAL | Decode 后 | Decode 后 |
| JALR | Decode 后 | 寄存器读后 |
| BRANCH(如 BLT) | Execute 后 | Decode 后 |
2. 静态与动态预测
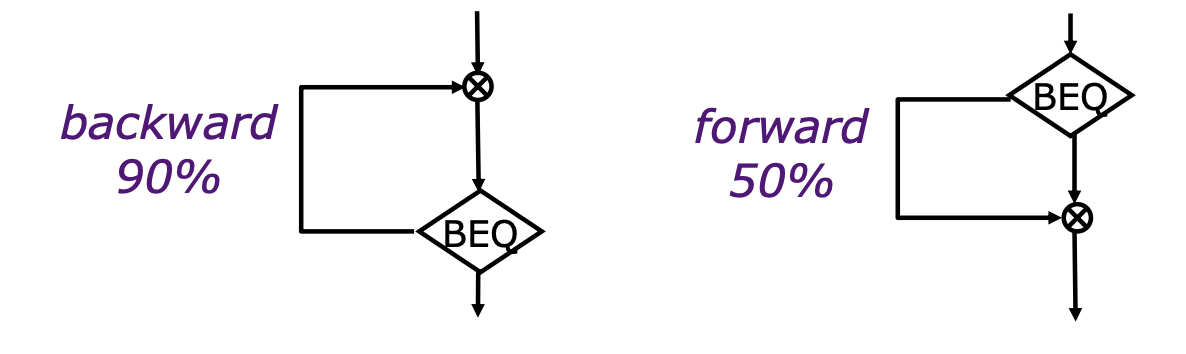
分支总体 taken 概率约 60–70%。ISA 可附"偏好方向"语义(如 MC88110),或允许编译器任选静态方向(PA-RISC、IA-64)。一个简单启发式:后向分支 90% taken(循环),前向分支约 50%。静态预测约 80% 准。
利用两类相关性:
• 时间相关 (temporal):某分支这次的结果是它下次结果的好预测。
• 空间相关 (spatial):多个分支可能高度相关地一起解析(偏好执行路径)。
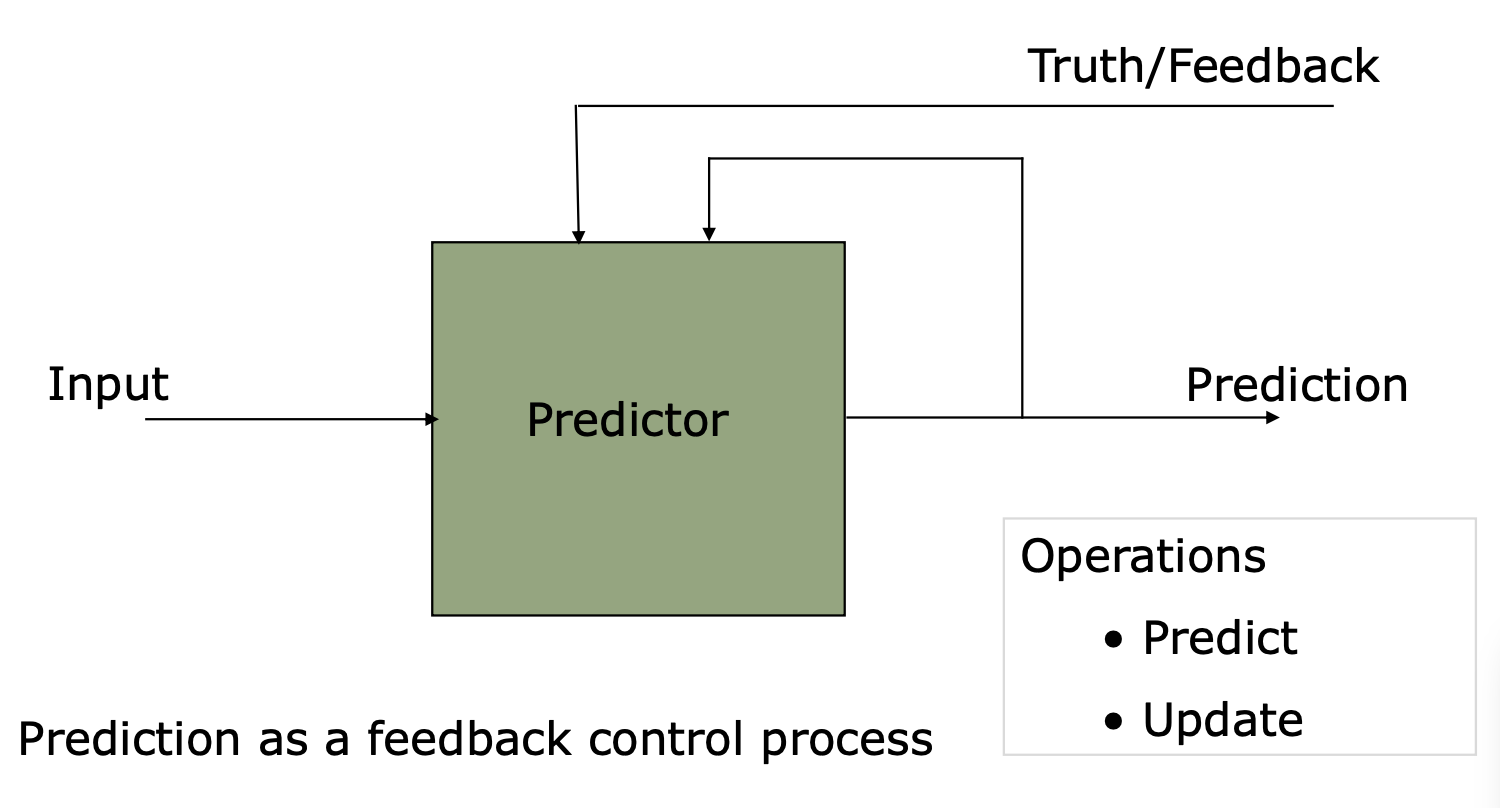
预测器原语 (Predictor Primitive,Emer & Gloy 1997):一张索引表,支持 Predict 与 Update,记作
3. 分支历史表 (BHT):1-bit 与 2-bit
$A21064(PC; T) = P[1, 2K](PC; T)$,用 PC 索引,存上次结果。
每次循环至少错两次(进入循环时一次、退出循环时一次)。
每项 2 位,管理为饱和计数器:11 强 taken、10 弱 taken、01 弱 not-taken、00 强 not-taken。方向预测只在连续两次错误后才改变,用 MSB 决定预测方向。
$A21164(PC; T) = \text{MSB}(\text{Counter}[2, 2K](PC; T))$
2-bit 把循环的错误预测从每循环 2 次降到 1 次。典型 4K 项 BHT、2 位/项,准确率 ~80–90%。为省空间,BHT 通常不打 tag(允许地址别名)。
4. 利用历史相关性的两级预测
历史寄存器记录处理器最近 N 个分支的方向。利用空间相关:如
if(x<7) 为假则 if(x<5) 也为假。$\text{History}(\text{Index}; T) = P(\text{Index}; P \,\|\, T)$。 几种组合方式:
- 全局历史 (Global):用全局历史索引计数器。
- 局部历史 (Local):用 PC 索引出该 PC 的局部历史,再索引计数器。
- GShare:
——把全局历史与 PC 异或后索引,兼顾全局模式与特定 PC。 - 两级预测器(Pentium Pro, 1995):用最近两个分支结果选 4 组 BHT 之一,~95% 准。
用一个选择器 (chooser) 学习"对下一分支用局部还是全局历史更好";全局历史推测更新、错误时恢复。在多种应用上声称 90–100% 成功。
多个用不同历史长度的带 tag 组件级联,以 Bimodal 为基底,逐级"若我命中且更可信则用我的猜测,否则回退到下一级"。每组件含 Counter / Useful / Tag,在错误预测时分配表项。是当代最强方向预测器家族。
5. 方向预测的局限 → 目标预测
方向预测器无法在目标地址确定前重定向取指流。即便正确预测 taken,仍要等目标算出——产生"正确预测 taken 分支的惩罚"和"寄存器跳转惩罚"。
5.1 分支目标缓冲 (Branch Target Buffer, BTB)
把预测目标地址(连同 BP 位)存起来,在 IF 段即决定 nPC:若预测 taken 则 nPC = target,否则 PC+4;稍后检查,错则 kill 并更新 BTB/BHT。
未打 tag 的 BTB 会让非控制指令(如 1028 处的 Add)误命中某分支表项,导致错误重定向。解决:给 BTB 项打 tag——只为 taken 分支/跳转保留项,匹配失败则取 PC+4。好处:消除 ALU 指令后的假预测,且腾出空间存更多分支目标,在分支被取指/译码前就定出 next PC。
BTB 项比 BHT 贵得多,但能在更早的流水段重定向、并加速间接分支 (JALR);BHT 项多、更准,放在较晚段纠正 BTB 漏掉的 taken 分支。二者都在分支于 E 段解析后更新。
5.2 返回栈 (Subroutine Return Stack)
① switch(同一 case 重复用得好);② 动态函数调用(同一类型虚函数好);③ 子程序返回——BTB 差,因为一个函数常被多处调用。
返回栈:调用时压入返回地址、返回指令译码时弹出,对返回比 BTB 准确得多(典型 8–16 项)。
行预测 (Line Prediction,Alpha 21x64):每周期预测要取的 cache 行(超标量下预测下一行),用未打 tag 的 BTB 结构,后续预测器再精化目标。
6. 分支预测全景
下一讲: Speculative Execution & Value Management(推测执行与值管理)
降低控制流惩罚的手段:软件侧——循环展开 (loop unrolling) 增加运行长度、指令调度尽早算分支条件(价值有限);硬件侧——旁路、延迟槽、准确推测(分支预测)。
指令执行阶段
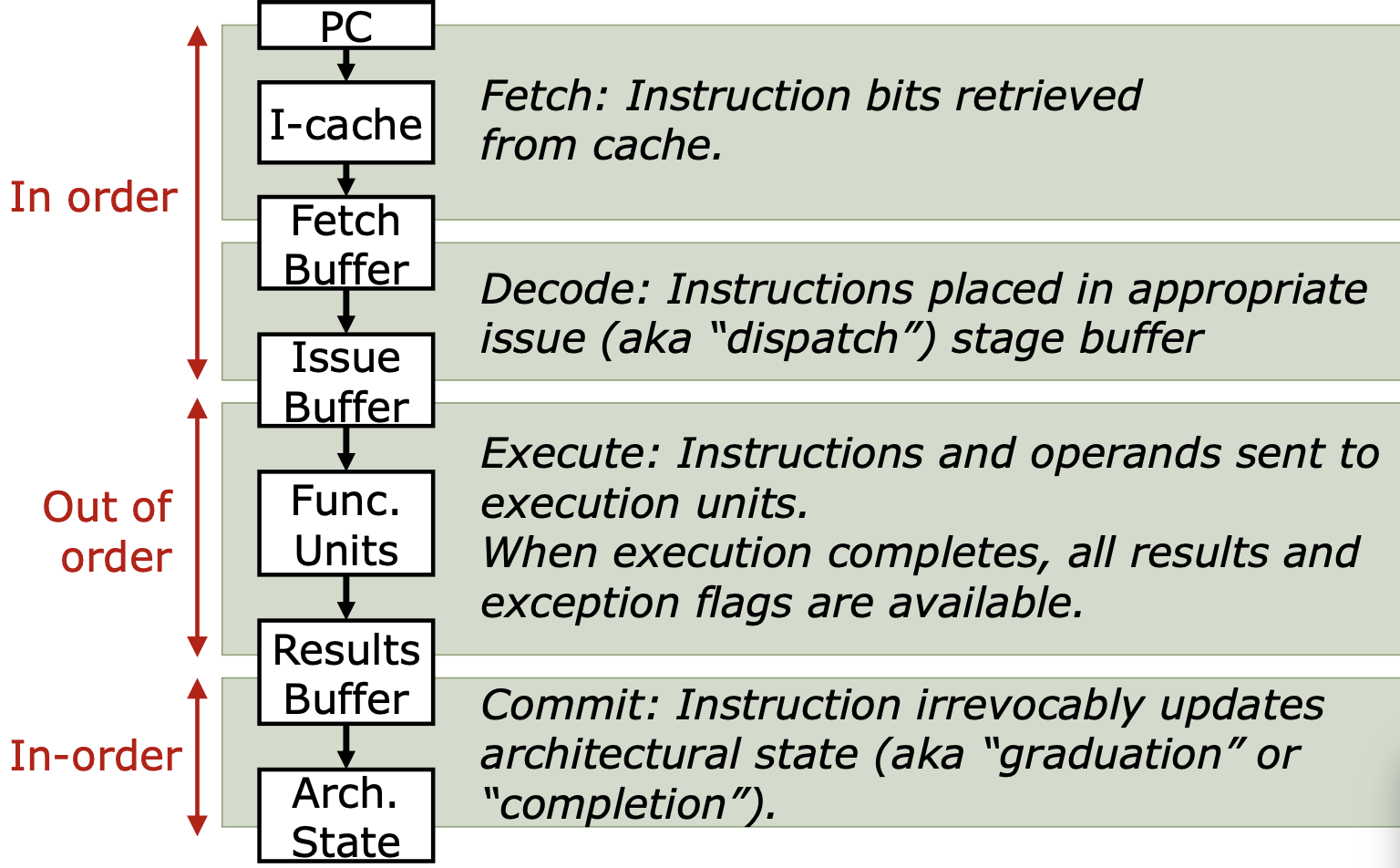
Fetch(取指)指从指令缓存(I-cache)中检索指令位的过程,并把即将执行的指令放到取指缓冲区(Fetch Buffer)
Decode(解码):是指将指令从取指缓冲区转移到适当的发射缓冲区(Issue Buffer),这个阶段处理器会分析指令的类型和操作数,并准备将其分发给死党的执行单元。这个阶段,指令会被译码
(Issue(发射)):是指从发射缓冲区将指令和操作数送往执行单元(Functional Units)的过程。在这一阶段,处理器会根据指令的类型和资源的可用性,决定将哪条指令送到执行单元。
执行阶段:在这一阶段,指令操作会在相应的功能单元中完成(例如ALU、FPU等),并生成结果。当执行完成时,所有的结果和异常标志都会变得可用。有些说法,是发射阶段也是作为执行阶段的一部分
Commit(提交阶段),在这一阶段,指令操作会在相应的功能单元中完成(例如ALU、FPU等),并生成结果。当执行完成时,所有的结果和异常标志都会变得可用。
控制流惩罚
现代处理器在下一条指令地址计算(next PC calculation)和分支决策(branch resolution)之间可能有超过10个流水线阶段。这意味着分支预测在现代处理器中的重要性,因为如果分支预测错误,会导致大量的指令无效,浪费处理器资源并影响性能。
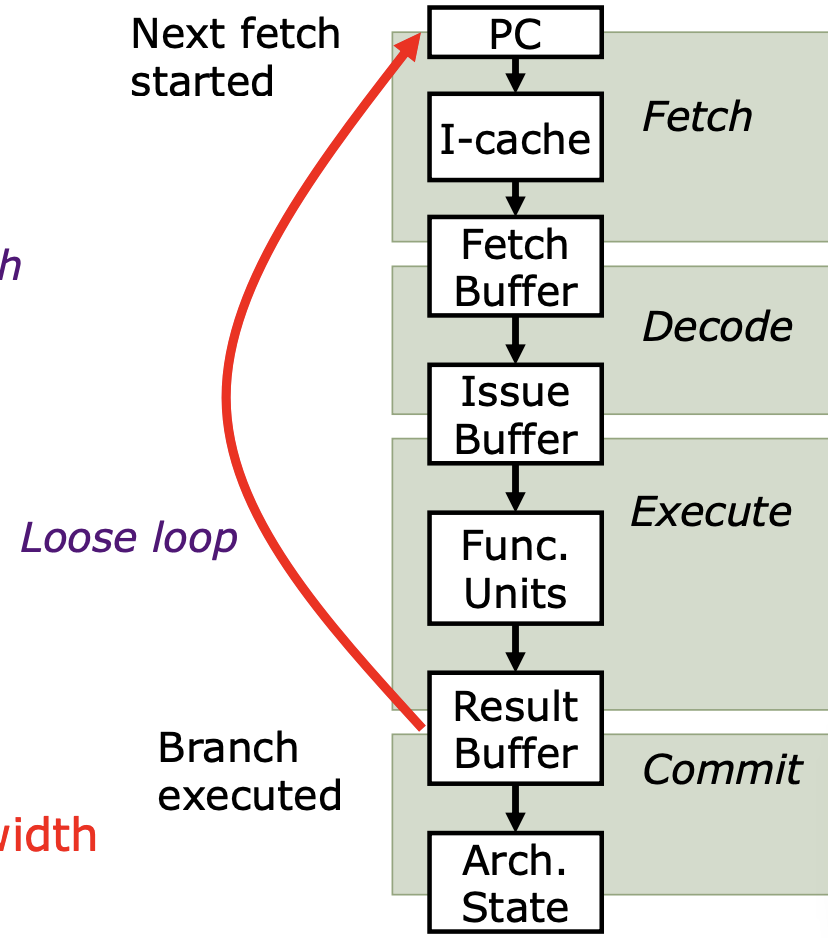
如果流水线没有遵循正确的指令流,即出现分支预测错误,处理器将丢失大量工作。这可以通过以下两个因素来理解:
- 流水线长度(Loop Length):指的是处理器流水线的深度,也就是指令从取指到完成所经过的阶段数。
- 流水线宽度(Pipeline Width):指的是每个时钟周期处理器可以同时处理的指令数量。
当出现分支预测错误时,处理器必须丢弃已经取出的错误指令,并重新从正确的分支路径取指。这意味着:
- 所有在错误路径上已经进入流水线的指令都需要被丢弃。
- 处理器必须重新取指,从正确的分支路径开始执行。
假设:
- L Loop length是流水线的长度,即流水线中从取指到提交所需的阶段数。
- W pipline width是流水线的宽度,即每个时钟周期可以同时处理的指令数量。
当分支预测错误时,处理器将丢失的工作量可以近似计算为:
根据提供的数据,SPEC CPU 2017的指令分布如下:
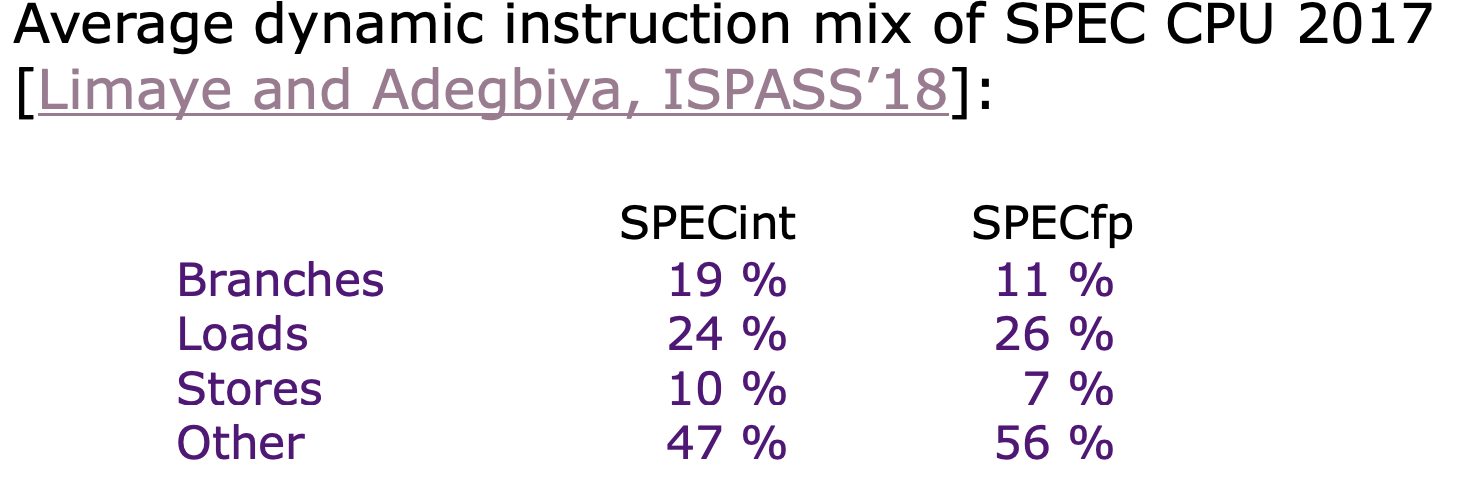
意味着在SPECint基准测试中,每5.26条指令中有一条是分支指令,SPECfp基准测试中,每9.09条指令中有一条是分支指令。 理解这些数据对于优化编译器和处理器设计,尤其是分支预测器的设计,具有重要意义。
RISC-V 分支和跳转
每条指令的fetch都需要依赖的前一条指令的信息。这些信息是:
- 前一条指令是否是一个“被执行”的分支指令。
- 如果是的话,目标地址是什么。
| 指令 | 分支指令是否被执行? | 目标地址? |
|---|---|---|
| JAL | 解码阶段后 | 解码阶段后 |
| JALR | 解码阶段后 | Reg. 取回后 |
| BRANCH(e.g., BLT) | 执行阶段后 | 解码后 |
JAL(Jump And Link):跳转指令,目标地址在解码阶段就可以确定,跳转行为也是在解码阶段确定的。
JALR(Jump And Link Register):跳转指令,目标地址依赖于寄存器的值,在寄存器取回阶段确定,跳转行为在解码阶段确定
条件分支指令(如 BLT):跳转行为在执行阶段确定,目标地址在解码阶段确定
为什么关心前一条指令是否是被执行的分支?
在处理器的流水线中,指令的取指(fetch)和执行是连续的多个阶段。如果前一条指令是一个被执行的分支指令,那么程序的执行流将发生跳转,这意味着:
- 处理器需要知道跳转的目标地址,以便正确地取回下一条指令。
- 处理器需要在合适的阶段确定前一条指令是否是一个被执行的分支,以便进行相应的处理
分支惩罚例子
UltraSPARC-III 是一种超标量处理器,它的指令获取流水线包含多个阶段。
4-way Superscalar:处理器可以在同一个时钟周期内并行发射最多4条指令进行执行。
In-order Issue:指令按照程序顺序(in-order)发射到执行单元
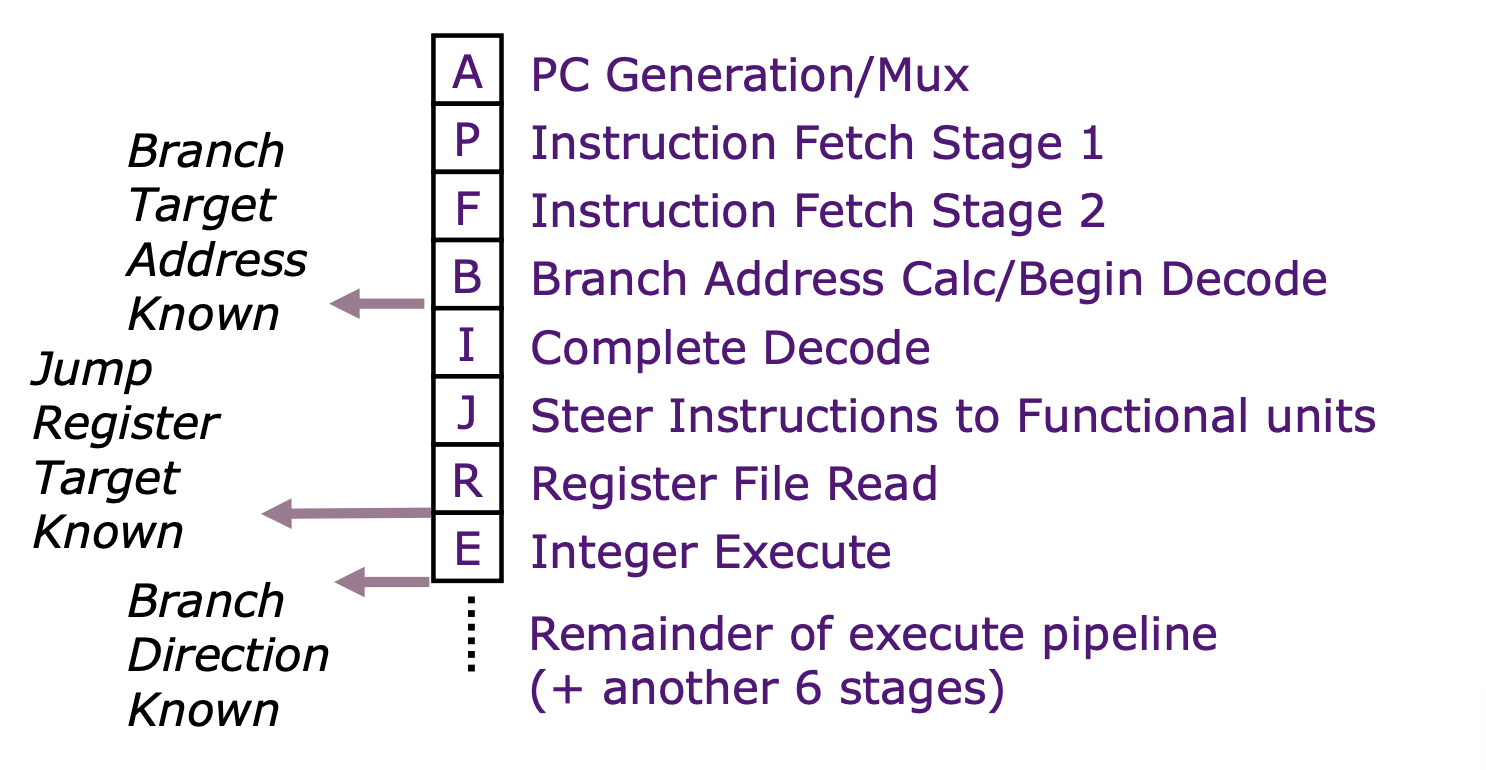
流水线阶段
- PC Generation/Mux 选择要取指的地址,是指令流水线的起点
- Instruction Fetch Stages (P, F) 负责从指令缓存中取指。
- Branch Address Calc/Begin Decode (B) : 分支地址计算/开始解码
- Complete Decode (I) 负责解码指令并处理分支指令的地址计算。
- Steer Instructions to Functional Units (J) 将解码后的指令分发到适当的执行单元。
- Register File Read (R) 读取需要的操作数。
- Integer Execute (E) 执行整数运算指令。
- Remainder of execute pipeline 涵盖了所有剩余的执行和写回阶段(+ 另外6个阶段)
如何减少控制流惩罚
软件层面:
- 消除分支——通过展开循环体
- 增加分支之间的运行长度
- 循环体展开是指将循环体重复多次
- 减少分支解析时间——通过指令调度
- 尽早计算分支条件
硬件层面:
- 旁路(Bypass)——立即使用计算结果
- 计算结果可以直接传递给需要使用的指令,而无需等待结果写回寄存器。减少数据依赖引起的流水线停顿。
- 改变架构——找其他事情做
- 使用延迟槽(delay slots),即在可能导致流水线停顿的地方插入有用的指令,这需要软件的配合
- 准确预测——分支预测的手段
- 对分支指令的结果进行预测,并在预测结果的基础上继续执行后续指令
分支预测
分支预测的动机
在深度流水线处理器中,分支指令(如条件跳转)如果预测错误,会导致流水线停顿或执行无用指令,从而影响处理器的性能。这种影响被称为分支惩罚(Branch Penalties)。为了提高处理器的效率,需要尽量减少分支惩罚
现代分支预测器的准确率已经超过95%,意味着它们在大多数情况下都能正确预测分支指令的结果,从而减少因分支指令引起的停顿和性能损失。
分支预测需要什么硬件支持?
预测结构:
- 分支历史表(Branch History Tables, BHT)
- 记录最近的分支行为历史,用于预测未来的分支行为。BHT通常会记录每个分支指令的执行情况(例如,是否跳转)
- 分支目标缓冲区(Branch Target Buffers, BTB):
- 存储分支指令的目标地址。每当遇到分支指令时,可以快速查找目标地址,从而减少计算分支目标地址的时间。
错误预测恢复机制(Mispredict Recovery Mechanisms)有哪些
当分支预测错误时,需要有效的机制来恢复到正确的状态:
- 将结果计算与提交分离(Keep result computation separate from commit):
- 处理器在执行指令时,先计算结果,但在确定分支正确性之前,不提交这些结果。这样可以避免错误结果提交到寄存器或内存中。
- 清除流水线中分支后的指令(Kill instructions following branch in pipeline):
- 如果分支预测错误,流水线中分支后的指令都需要被清除,以避免错误指令继续执行。
- 恢复状态到分支之后的状态(Restore state to state following branch):
- 恢复处理器状态到分支指令之后的状态,包括恢复程序计数器(PC)、寄存器状态等。这样处理器可以从正确的状态继续执行。
静态分支预测
总的来说, 一个分支指令被接受的概率是60~70%,这意味着在大多数情况下,分支指令会执行跳转操作。但是
ISA 为分支指令附加“偏好跳转”或“偏好不跳转”的语义,处理器可以在缺乏其他预测信息时,依据这些偏好来做出初步预测。这种设计能够帮助处理器在大多数情况下做出更准确的预测,从而减少因错误预测带来的性能损失。
比如bne0 (preferred taken) beq0 (not taken)
ISA 可以允许任意选择静态预测方向。指令集架构可以在不同的应用场景下灵活应对分支预测的需求
动态预测:基于过去的行为学习
分为两种相关性:
- 空间相关性(Spatial correlation):空间相关性指的是多个分支指令在程序的空间位置上可能会以高度相关的方式解决。这意味着某些分支指令在特定的执行路径中经常会以相似的方式解决。空间相关性可以通过分析程序的结构或静态分析来推断,而不需要实际运行时数据。
- 时间相关性(Temporal correlation): 分支指令在不同执行周期中解决的方式可能存在关联。换句话说,如果一个分支指令在上一次执行时采取了某种分支路径(例如跳转或不跳转),那么在下一次执行时,它很可能以相同的方式解决。这种相关性源于程序执行的局部性原理,即程序的执行在短期内往往会表现出相似的行为模式
时间相关性 分支的解析方式可以很好地预测它在下一次执行时的解析方式 空间相关性 多个分支可能以高度相关的方式解析(首选的执行路径)