Lec 11 多线程技术
流水线冒险(Pipeline Hazards)

LW r1, 0(r2)
LW r5, 12(r1)
ADDI r5, r5, #12
SW 12(r1), r5每个指令可能取决于之前的一个,这种情况下要怎么处理?
虽然旁路(bypassing)、推测执行(speculation)和乱序执行(out-of-order execution,O-O-O)可以在一定程度上缓解这些延迟,但它们不能完全消除所有的延迟。
我们如何保证指令之间没有依赖呢?
从不同的程序里面取指令
我们有四个线程(T1到T4),它们的指令将在一个没有旁路功能的5级流水线中交错执行。
假设我们有以下顺序的指令:
- T1:
LW r1, 0(r2) - T2:
ADD r7, r1, r4 - T3:
XORI r5, r4, #12 - T4:
SW 0(r7), r5 - T1:
LW r5, 12(r1)¥
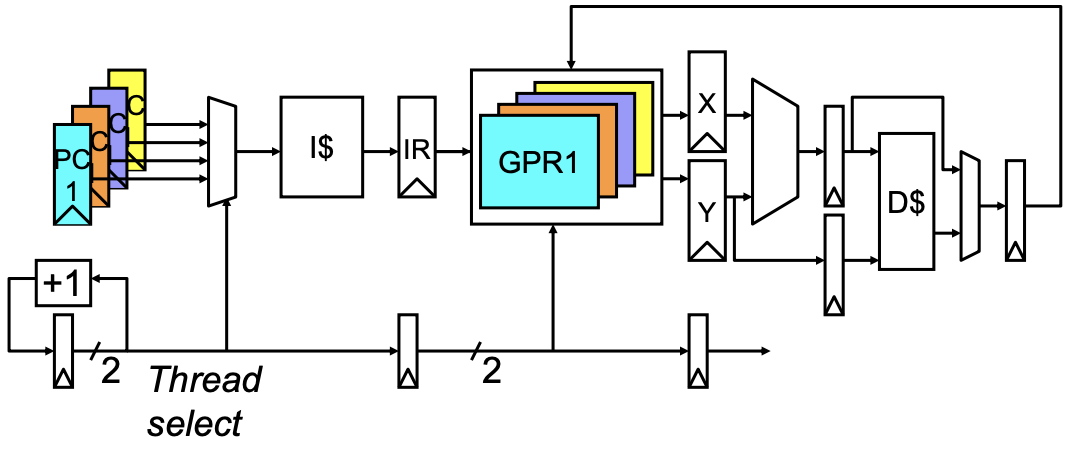
在同一个线程中的前一条指令总是在下一条指令读取寄存器文件之前完成写回(write-back)
简单单线程流水线
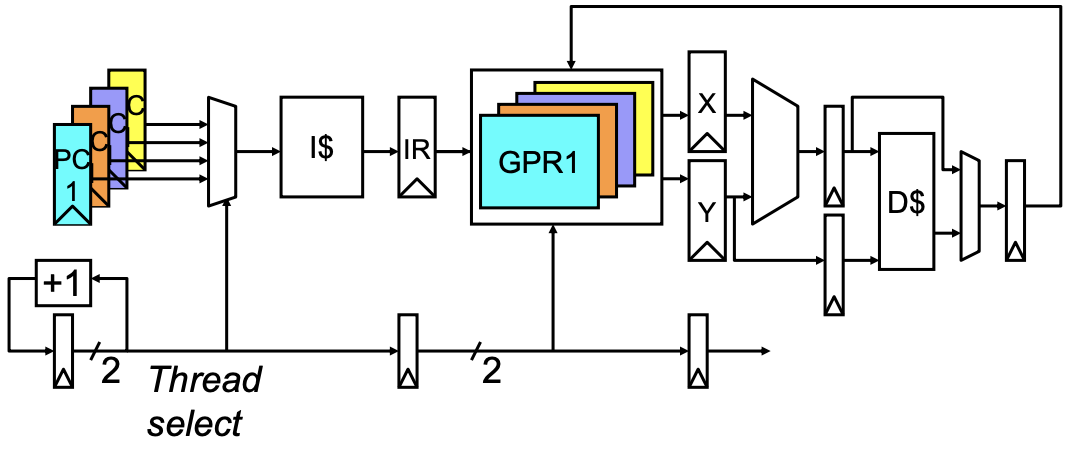
简单多线程流水线
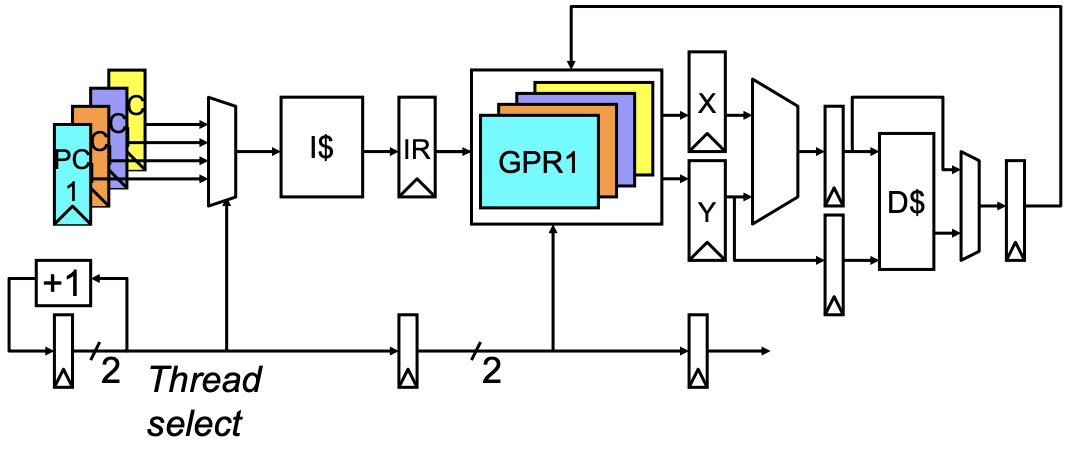
为了确保每个流水线阶段正确地读取和写入状态位,必须在流水线中传递线程选择信息。
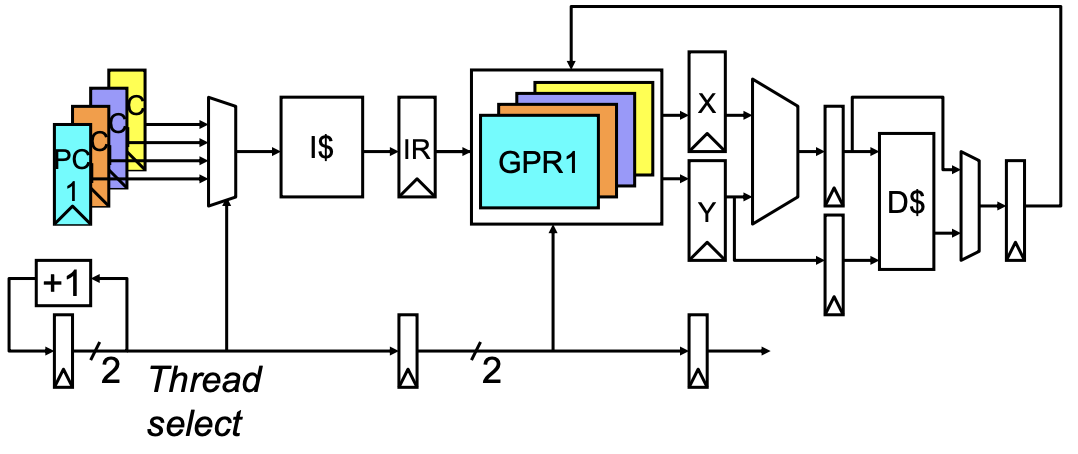
需要在流水线中传递线程选择信息。这可以确保每个阶段知道当前处理的是哪个线程的指令,从而访问和修改正确的状态位,避免线程之间的混淆和数据不一致。
多线程的开销
每个线程需要自己的用户架构状态
程序计数器(PC)
通用寄存器(GPRs)
还有系统架构状态
- 虚拟内存页基址寄存器
- 异常处理寄存器
其他成本
- 上下文切换开销
- 共享资源管理
- 复杂硬件设计
在软件(包括操作系统)看来,就像是多个 CPU,虽然速度较慢
线程调度策略
- 固定交错执行(CDC 6600, 1965)
- 每个线程在每N个周期中执行一条指令。
- 例如,如果有N个线程,则每个线程在固定的时间间隔内交替执行指令。
- 如果某个线程在它的时隙中没有准备好执行指令,则在流水线中插入一个空泡(pipeline bubble)
- 软件控制的交错(T1 ASC PPUs, 1971)
- 操作系统(OS)在N个线程中分配S个流水线时隙。
- 硬件在这S个时隙中进行固定交错,执行分配到这些时隙中的线程。
- 硬件控制交错(HEP 1982)
- 硬件跟踪哪些线程准备好执行指令。
- 根据硬件优先级方案选择下一个要执行的线程。
使用硬件线程的机器
1、

2、

架构

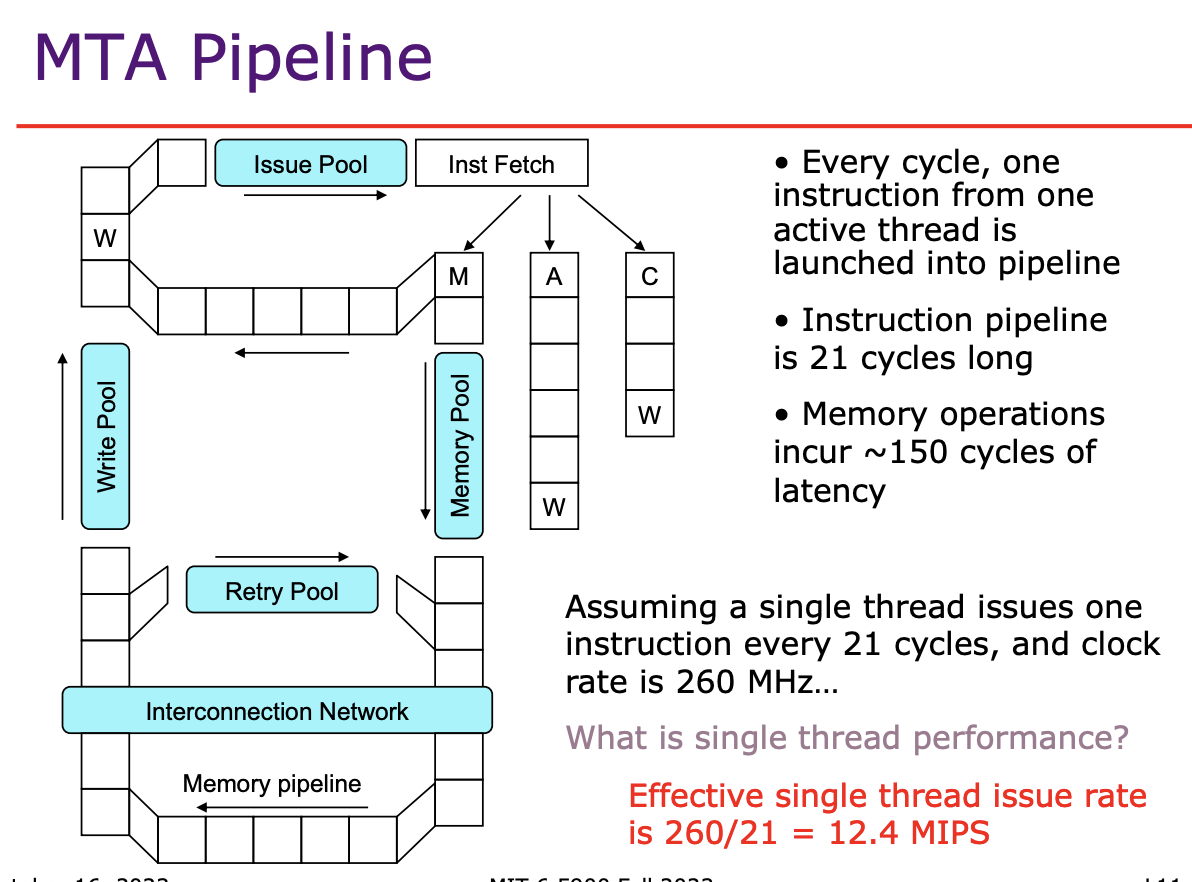
Coarse-Grain 粗粒度多线程
定义:每个时钟周期都会在不同的线程之间进行上下文切换。
优点:
- 高效隐藏单个线程的延迟(例如,内存访问延迟)。
- 能够平滑地在多个线程之间分配处理器资源。
缺点:
- 上下文切换频繁,可能增加开销。
- 需要支持多个线程的硬件状态(寄存器、PC等)。
适应性:
应用有高并行性和高延迟操作(如大量内存访问)。
需要充分利用处理器的每个时钟周期
Fine-grained 细粒度多线程
定义:每隔几个时钟周期进行一次上下文切换,通常在出现某些事件时切换,如功能单元数据危害(data hazard)、L1缓存未命中、L2缓存未命中等
优点:
- 上下文切换频率低,降低了切换开销。
- 适用于线程间依赖性较少的场景。
缺点:
- 在单个线程遇到延迟时,其他线程可能无法充分利用处理器资源。
适应性:
应用的并行性较低,线程之间的依赖性较少。
希望减少上下文切换带来的开销。
奔腾-4 超线程(2002)
- 首个商用SMT(同时多线程技术)设计(2路多线程)
- 超线程=SMT
- 逻辑处理器共享几乎所有物理处理器资源
- 一个物理处理器核心被分成两个逻辑处理器。尽管它们在操作系统中表现为两个独立的处理器,但它们共享大部分硬件资源,如缓存、执行单元和分支预测器
- 超线程的芯片面积开销约为5%
- 当一个逻辑处理器停顿时,另一个可以继续运行
- 在两个线程活跃时,没有一个逻辑处理器可以使用队列中的所有条目
- 处理器运行单个活跃软件线程时,性能几乎不受超线程影响
- 如果处理器只运行一个活跃的线程,开启或关闭HT技术对性能几乎没有影响。这是因为一个逻辑处理器可以独占使用所有共享资源。
前端
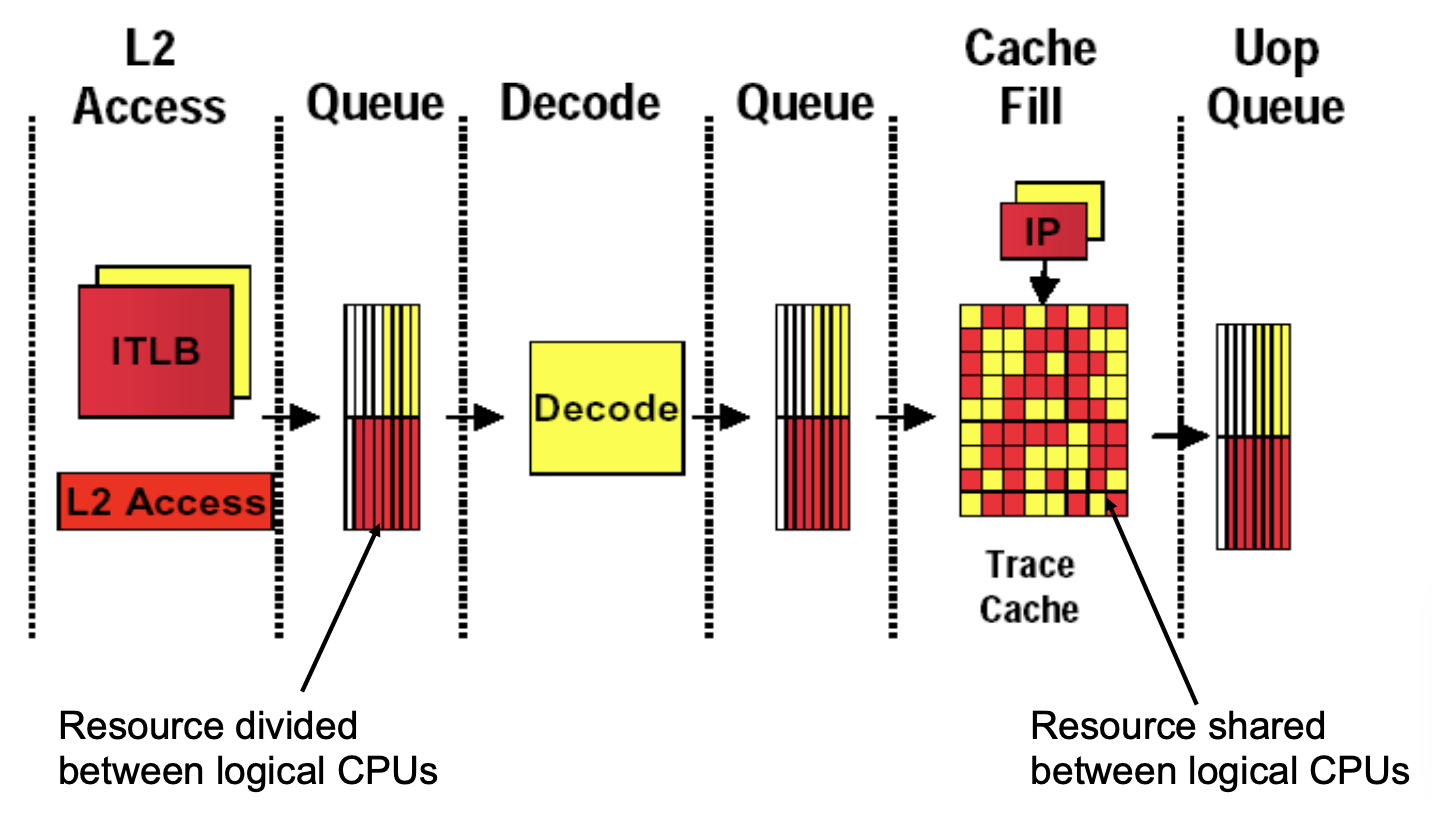
分支预测
为什么要独立的返回地址栈
解释: 在程序执行过程中,函数调用和返回会使程序跳转到不同的地址。返回地址栈用于存储函数返回地址,以便在函数结束时能够正确返回调用点。在多线程环境中,如果多个线程共享同一个返回地址栈,那么一个线程的函数返回地址可能会被另一个线程的函数调用覆盖,导致错误的返回地址和程序崩溃。
为什么要有独立的一级全局分支历史表?
解释: 分支预测依赖于分支历史信息来预测未来的分支走向。一级全局分支历史表记录了最近的分支走向历史。在多线程环境中,如果多个线程共享同一个一级全局分支历史表,不同线程的分支历史会相互干扰,导致预测准确性下降。
为什么共享的二级分支历史表,并标记逻辑处理器ID?
解释: 二级分支历史表(通常是一个模式历史表)用于存储模式和相应的分支结果。通过共享二级分支历史表,可以减少硬件资源开销,提高资源利用率。但是,为了防止不同线程的分支历史相互干扰,需要使用逻辑处理器ID对条目进行标记,以区分不同线程的分支历史。
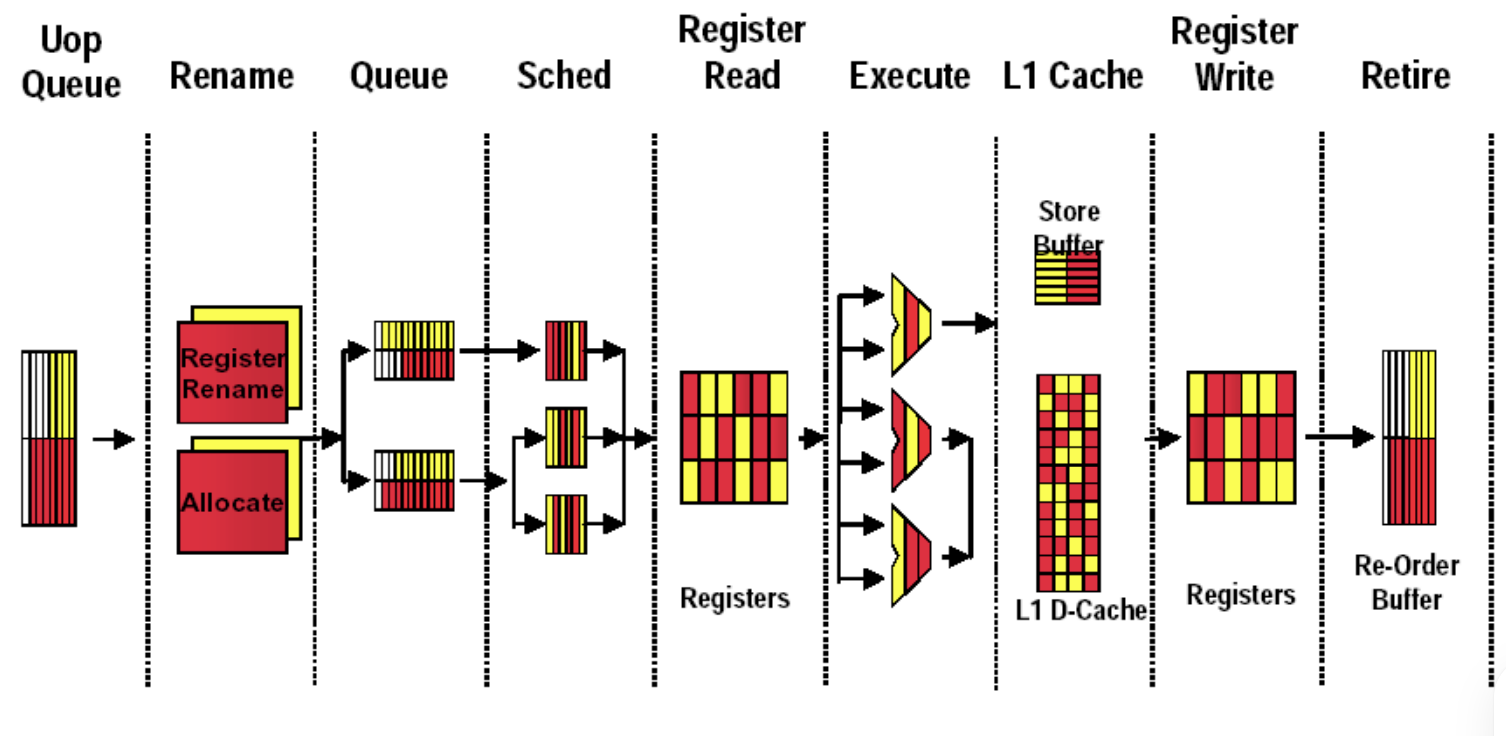
执行流水型
总结
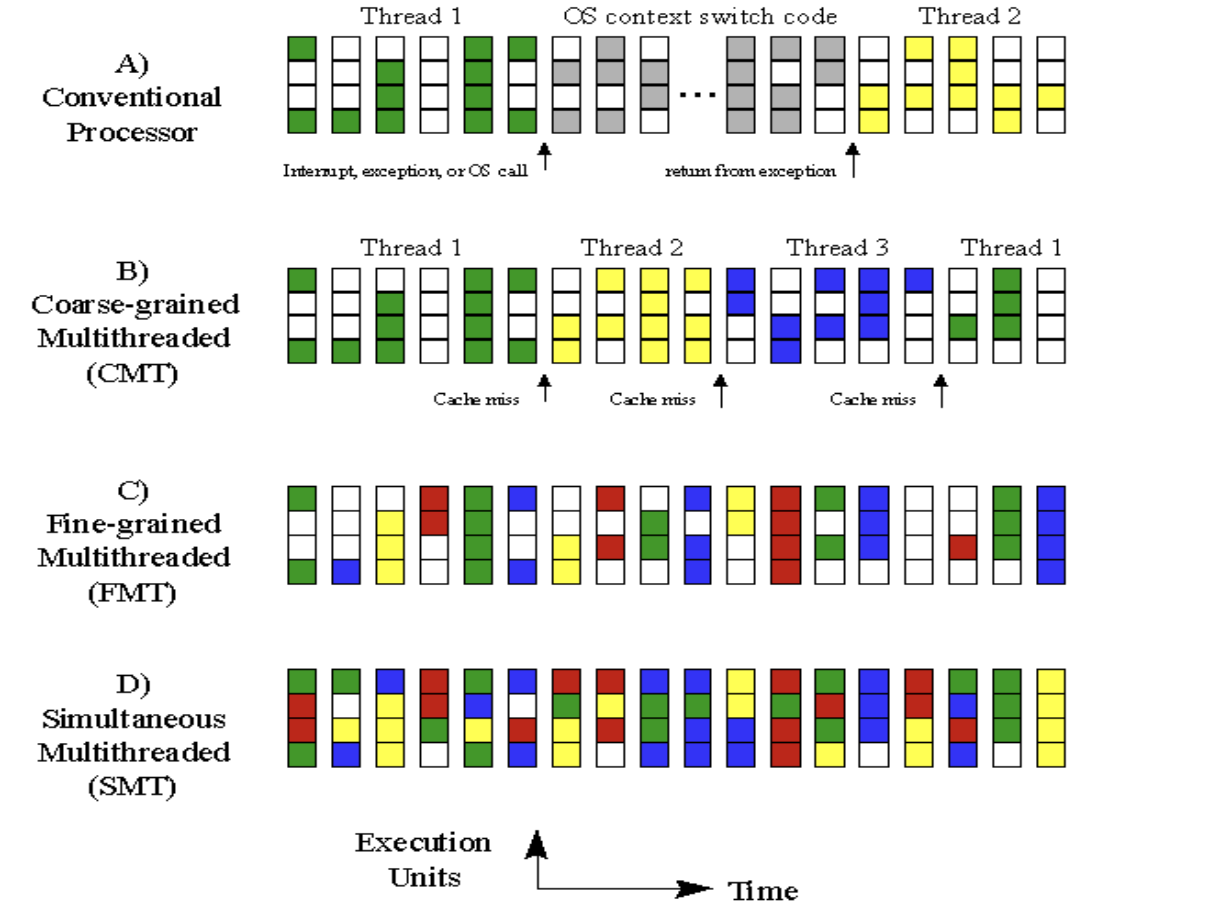
交叉领域主体,因为它涉及到流水线和超标量技术,GPU和多处理器技术。线程有自己状态和当前的PC。