Lec 2 ISA
历史回顾
IBM 650
1953年,第一台大规模制造的计算机,

其存储器介质是磁鼓。简单理解为金属圆筒表面覆盖磁性材料,以恒定速度旋转。地址是线性编号的,每个字(word),是10 位十进制数 + 1 位符号位。20位的上/下累加器。具体的原理略过。
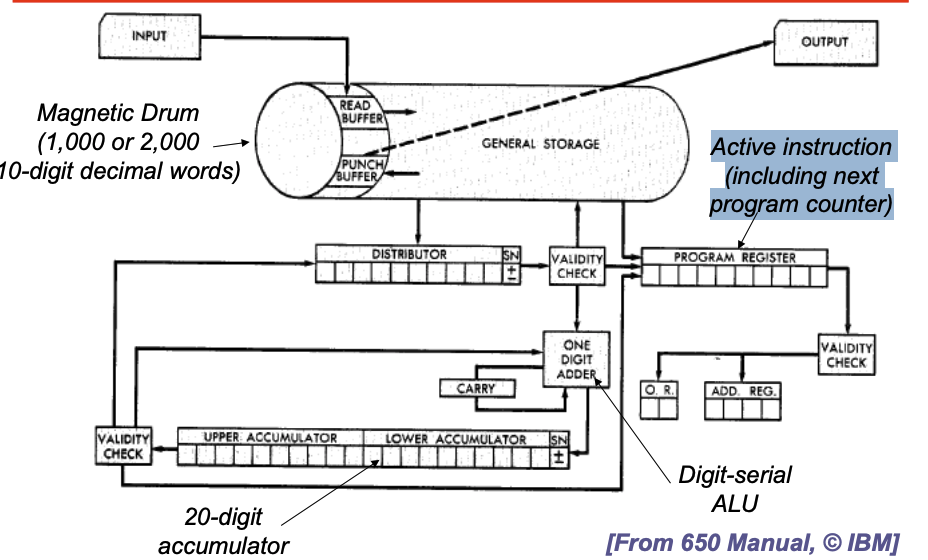
我们以程序猿视角理解这台机器,假如收到指令为60 1234 1009
- 从内存地址 1234(在磁鼓上)读出一个十进制数据字,将其加载到分配器(Distributor)寄存器中,同时也放入到上累加器,并将下累加器清零;然后跳转到内存地址1009,执行下一条指令。
- 程序员对机器的理解与其硬件实现是密不可分的。
- 优秀的程序员会根据磁鼓的旋转特性来优化指令的存放位置,以减少等待延迟
IBM 360
1964年,System/360 的一个主要目标是打造统一的架构平台,可以从低端到高端多个型号共用一个指令集(ISA)。
- 必须有通用的方法来连接 I/O 设备
- 关注的是总吞吐量,而不仅仅是每秒传输多少位
- 机器必须能够自主管理运行状态,无需人工干预
- 硬件必须内建故障检测和定位机制,以减少宕机时间
- 系统易于组合,并支持冗余的 I/O 和内存,以增强容错性
- 某些问题需要浮点字长大于 36 位
处理器状态 & 数据类型
”在一条指令执行结束后,处理器内部保存的信息,为下一条指令的执行提供上下文“,比如PC、累加器等
寄存器中保存的数据有具体类型,如整数、浮点数、地址等,执行指令时会根据指令定义的类型对数据进行操作。硬件和指令集定义了这些数据的“含义”和“处理方式”
如果指令执行过程中可能被中断,硬件必须以对程序透明的方式保存和恢复处理器状态。
指令集
控制处理器中数据变化的方式,是由指令集架构(ISA)所提供的指令来决定的。ISA 必须定义的内容包括:
- 如何访问寄存器和内存(例如
R1,[R2+4],0x1000这样的寻址方式) - 有哪些计算操作(如加法、乘法、与、或、比较等)
- 如何控制指令的执行顺序(如跳转、函数调用、条件分支)
- 这些指令如何表示为二进制(机器语言的格式,供 CPU 直接执行)
而且, ISA 必须满足软件的需要。特别是以下几类软件,编译器、汇编器、OS、VM
通用寄存器机器
IBM 360是通用寄存器机器,在处理器状态方面,有16个32位的寄存器,4个64位浮点数寄存器,以及一个程序状态字(Program Status Word PSW),可以理解一个区域,包含有PC、Condition code和控制位。
数据类型:单字节、双字节、32-bit字、64-bit;
24位地址的32位的机器,但没有指令能包含24-bit的地址
不同型号的技术参数
| 项目 | Model 30 | Model 70 |
|---|---|---|
| 内存容量 | 8K - 64KB | 256K - 512KB |
| 内存周期(Memory Cycle) | 2 微秒 | 1 微秒 |
| 数据通路宽度(Datapath) | 8 位 | 64 位 |
| 电路延迟(Circuit Delay) | 主存中每一层 30 纳秒 | 晶体管中每一层 5 纳秒 |
| 寄存器(Registers) | 使用只读存储器(Read-only) | 专用电路(Dedicated circuits) |
| 控制存储器(Control Store) | 只读使用(Read only usec) | 专用硬件 |
IBM 最新大型机处理器——z15为例

- 92 亿个晶体管,12 核设计 → 每个处理器芯片集成了 92 亿个晶体管,包含 12 个核心。
- 每个系统最多 190 个核心(含 2 个备用核心) → 单个系统可配置 最多 190 个处理器核心,另外还有 2 个备用(spare)核心,用于容错或替换损坏的核心。
- 5.2 GHz 主频,采用 14 纳米 CMOS 工艺 → 每个核心的运行速度为 5.2 GHz,制造工艺是 14nm CMOS。
虚拟地址空间
- 64 位虚拟寻址(virtual addressing) → 支持 64 位的虚拟地址空间,可以访问的地址范围极大(相当于 2⁶⁴ 字节的理论空间)。
- 原始 IBM 360 是 24 位,IBM 370 扩展为 31 位 → IBM 的虚拟地址从最初的 24 位(360) 扩展到 31 位(370),再演化为现在的 64 位系统。
指令执行机制
- 超标量(superscalar)、乱序执行(out-of-order) → 每个周期可以同时发出多条指令,并且指令可以不按顺序执行,只要满足数据依赖。
- 最多同时发出 12 条指令(12-wide issue) → 每个周期最多可以同时发送 12 条指令 到执行单元。
- 最多允许 180 条指令在飞行中(in flight) → 指令可以在不同阶段同时进行处理,最多可有 180 条指令在执行流水线中。
分支预测支持
- 16K 项分支目标缓冲区(Branch Target Buffer, BTB),分支预测模块使用一个容量为 16K 项 的 BTB 来提高跳转指令预测准确率,优化商业负载
缓存系统:四级缓存结构
- 一级指令缓存(L1 I-cache):128KB
- 一级数据缓存(L1 D-cache):128KB
- 每个核心的二级缓存(L2):4MB
- 片上共享三级缓存(L3):256MB
- 片外共享四级缓存(L4):960MB
性能铁律

- 每程序指令取决于源代码、编译器技术和ISA
- 每指令周期数取决于ISA和微架构
- 每周期时间取决于微架构和制造工艺
| 微架构类型 | CPI | 时钟周期长短 | 性能特点 |
|---|---|---|---|
| Microcoded | >1 | 短 | 处理复杂指令,速度慢但灵活 |
| Single-cycle unpipelined | 1 | 长 | 实现简单,性能低 |
| Pipelined | ≈1(平均) | 短 | 高性能现代设计,复杂但高效 |