Lec 10 SDN 网络
流量管理和工程历来是一个非常具有挑战性的任务:它要求网络运营商调整路由协议的配置参数,从而重新计算路由。流量会沿着新的路径流动,导致流量的重新平衡。不幸的是,这种流量控制机制是间接的:路由配置的变化会导致网络内部和网络之间的路由发生变化,而这些协议可能会以不可预测的方式相互作用。SDN(软件定义网络)旨在解决这些问题
A. Greenberg et al., A Clean Slate 4D Approach to Network Control and Management, SIGCOMM CCR 2005.
Watch Scott Shenker's ONS’11 talk.
(Optional) M. Caesar et al., Design and Implementation of a Routing Control Platform, NSDI 2005.
(Optional) M. Casado et al., Ethane: Taking Control of the Enterprise, SIGCOMM 2007.
VFP: A Virtual Switch Platform for Host SDN in the Public Cloud
Firestone
NSDI 2017
B4: Experience with a Globally-Deployed Software Defined WAN
- A. Gupta et al., SDX: A Software Defined Internet Exchange, SIGCOMM 2014. (Presenter: Austin)
大纲
- SDWAN
论文阅读: SDN历程
The Road to SDN: An Intellectual History of Programmable Networks, SIGCOMM'2014.
摘要
SDN实际上是计算机网络可编程化努力的长期历史的一部分。本文回顾了可编程网络的历史,包括主动网络(active networks)、早期的控制平面与数据平面分离的努力以及近年来关于OpenFlow和网络操作系统的研究。我们强调了关键概念,以及推动每项创新的技术推动力和应用需求。同时,我们也揭穿了关于这些技术的常见误解,并澄清了SDN与相关技术(如网络虚拟化)之间的关系。
1. 引言
“SDN”这个词是在斯坦福大学的OpenFlow项目文章中首次提出的。计算机网络是复杂且难以管理的。网络管理员通常使用不同厂商的配置界面来配置单个网络设备,甚至同一厂商的不同产品也可能有不同的界面。尽管一些网络管理工具提供了中央视角来配置网络,但这些系统仍然在单个协议、机制和配置接口的层面上运作。
软件定义网络(SDN)正在改变我们设计和管理网络的方式。SDN有两个主要特点。首先,SDN将控制平面(决定如何处理流量)与数据平面(根据控制平面做出的决策转发流量)分离。其次,SDN将控制平面集中化,使得单个软件控制程序能够控制多个数据平面元素。SDN控制平面通过明确的应用程序接口(API)直接控制网络中数据平面元素(即路由器、交换机和其他中间设备)的状态。OpenFlow就是这样一个API的典型例子。OpenFlow交换机有一个或多个数据包处理规则表,每个规则匹配部分流量并对匹配的流量执行特定操作;这些操作包括丢弃、转发或泛洪。根据控制器应用程序安装的规则,OpenFlow交换机可以像路由器、交换机、防火墙、网络地址转换器,或两者之间的某种设备一样工作。
2. 通往SDN的道路
本节回顾了早期可编程网络的工作。我们将这段历史分为三个阶段,如图1所示。每个阶段对历史的贡献如下:(1)主动网络(从1990年代中期到2000年代初),引入了网络中的可编程功能以实现更大的创新;(2)控制平面和数据平面的分离(大约从2001年到2007年),开发了控制平面和数据平面之间的开放接口;以及(3)OpenFlow API和网络操作系统(从2007年到2010年左右),代表了开放接口广泛采用的第一个实例,并开发了使控制-数据平面分离可扩展且实用的方法。
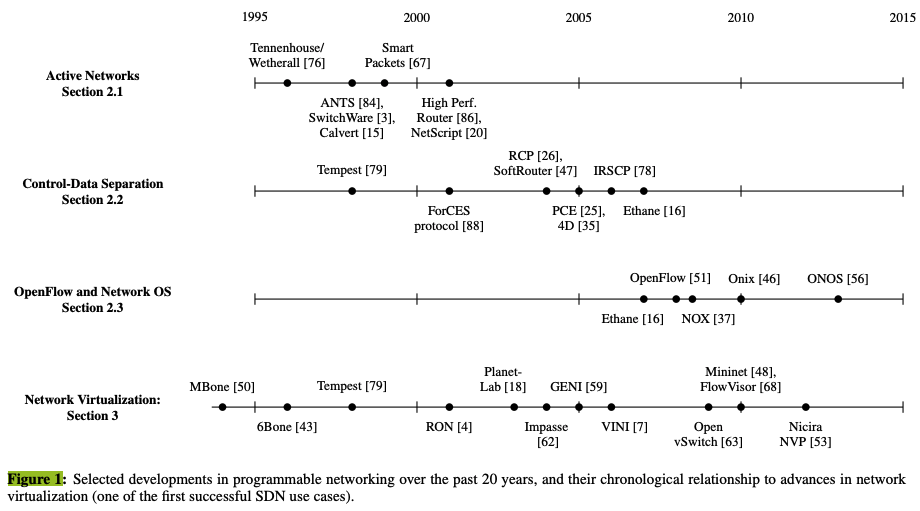
网络虚拟化在SDN历史演变中发挥了重要作用,早于SDN并成为SDN最早的重要应用之一。我们在第三部分探讨了网络虚拟化及其与SDN的关系。
2.1 主动网络
20世纪90年代早中期,互联网迅速发展,一些网络研究人员,渴望测试并部署新的网络服务改进方案。为了测试和模拟,选择了一种开放网络控制的替代方法,灵感部分来源于独立PC的易重编程性。具体而言,传统网络并非真正意义上的“可编程”。主动网络代表了一种激进的网络控制方法,通过设想一个暴露网络节点资源(如处理能力、存储、数据包队列)并支持对通过节点的部分数据包应用定制功能的编程接口(或网络API)。这种方法与互联网社区许多人的主张背道而驰,他们认为网络核心的简洁性是互联网成功的关键。
主动网络社区探索了两种编程模型:
- 胶囊模型:代码通过数据包内嵌带入节点执行;
- 可编程路由器/交换机模型:通过带外机制(如程序协议)来在节点上建立代码执行。
胶囊模型被视为主动网络的核心理念,而两种模型都在后续发展中留有遗产。胶囊模型设想在网络上安装新的数据平面功能,通过数据包携带代码(类似于早期的数据包无线电工作),并使用缓存提高代码分发的效率。而可编程路由器则将扩展性的决策权直接交给了网络运营者。
技术的推动和需求拉动:主动网络的发展,其推动力是受到DARPA(美国国防高级研究计划局)的资助支持,也受到了需求拉动,主要问题包括网络服务提供商对开发和部署新服务的长时间感到不满("网络僵化",network ossification),第三方对细粒度控制,以及研究人员对大规模实验的平台需求,以及中间设备激增的管理问题。这些需求在网络功能虚拟化(NFV)中得到了呼应,NFV也旨在为复杂中间设备功能的网络提供统一的控制框架。
知识贡献:
- 可编程化网络能够降低创新门槛。主动网络研究率先提出可编程网络的概念,以降低网络创新的门槛。这一概念表明,在生产网络中创新存在困难,并呼吁增加可编程性,这也是SDN的初始动机之一
- 网络虚拟化及基于数据包头部的解复用至软件程序。用来支持多种网络功能和编程模式在同一网络节点上运行。
- 网络虚拟化是指通过技术手段将单一的网络设备(如路由器或交换机)划分为多个虚拟的网络环境,使不同的应用程序或服务能够在这些虚拟环境中独立运行。
- 解复用是指通过分析数据包的头部信息,将数据包分发到合适的“执行环境”(Execution Environment,EE)中。每个EE对应一个虚拟化的环境,可以运行特定的应用程序或处理逻辑
- 为实现这种解复用,主动网络引入了“NodeOS”,即共享节点操作系统,它在每个节点上管理虚拟化的资源,并提供机制将数据包引导至合适的执行环境
- 统一中间设备编排的愿景。尽管主动网络研究计划未完全实现这一愿景,但早期设计文件提到了需要使用通用、安全的编程框架来统一各种中间设备功能。
误解:主动网络的研究中包含了为端用户提供网络API的想法,尽管大多数研究者认为终端用户作为网络程序员的情况很少见【15】。对于主动网络的一个误解是,数据包将携带由终端用户编写的Java代码,从而让一些人认为主动网络研究过于偏离真实网络,且不安全。此外,主动网络因无法提供实际性能和安全性而受到批评。
追求实用性:虽然主动网络阐述了可编程网络的愿景,但其技术并未得到广泛应用。主动网络研究的一个重大教训是数据平面的“杀手级”应用很难构思。
2.2 控制平面和数据平面分离
在2000年代早期,随着网络流量的增长以及对网络可靠性、可预测性和性能的要求越来越高,网络运营商开始寻求更好的网络管理方式,比如对流量路径的控制(即流量工程, traffic engineering)。传统路由协议支持的流量工程手段较为有限,令运营商感到沮丧。这一需求被一些与骨干网络运营商关系密切的研究人员注意到,促使他们探索了一些实用且基于现有协议或即将标准化的解决方案。
传统的路由器和交换机中,控制平面和数据平面紧密集成在一起,这使得很多网络管理任务(如调试配置问题、预测和控制路由行为)变得非常困难。为了解决这些问题,控制平面和数据平面的分离概念逐渐形成。
技术的推动和应用拉动:在1990年代互联网迅速发展期间,骨干网络的链路速度迅速增长,设备厂商开始将数据包转发逻辑直接在硬件中实现,控制平面软件则保持独立。此外,互联网服务提供商(ISP)也在努力管理日益扩大的网络规模、提高可靠性并开发新服务(如虚拟专用网络)
同时,商品化计算平台的进步使服务器的内存和处理资源大大超过了早期路由器的控制平面处理器。这些趋势促成了以下两个创新:
- 控制平面和数据平面之间的开放接口,如由互联网工程任务组(IETF)标准化的ForCES(转发和控制元素分离)接口,以及Linux内核中的Netlink接口。
- 网络的逻辑集中控制,例如路由控制平台(RCP)和SoftRouter架构,以及IETF的路径计算元素(PCE)协议。
这些创新主要是为了满足ISP内部路由管理的需求。相比主动网络研究,这些项目专注于网络管理员的创新,强调的是控制平面的可编程性以及网络范围的控制和可见性,而非设备级的配置。
网络管理应用,包括基于当前流量负载选择最佳路径等一些控制应用在ISP运营商中运行。将控制功能从网络设备中移至独立服务器具有实际意义,因为网络管理本质上是一个网络范围的活动。逻辑集中式路由控制器得益于开源路由软件的兴起,这使得开发原型实现的门槛大大降低。随着服务器技术的进步,一台普通服务器能够存储大量ISP网络的路由状态并计算所有的路由决策,从而实现简单的主备复制策略,以保证控制器的可靠性。
知识贡献:控制平面和数据平面分离的初步尝试相对实用,但它们从概念上显著偏离了互联网的传统,即路径计算和数据包转发紧密耦合的模式。但是为后续的SDN设计带来了几点贡献作为参考:
- 通过开放接口实现逻辑集中控制。
- 分布式状态管理。逻辑集中式路由控制器面临分布式状态管理的挑战。为应对控制器故障,控制器需进行复制,但这可能导致状态不一致
2.3 Openflow 和 网络操作系统
在 OpenFlow 出现之前,SDN(软件定义网络)相关的理念在实现完全可编程网络的愿景和实际可部署性的需求之间存在张力。OpenFlow 通过基于已有的交换机硬件,来扩展功能,在这两个目标之间找到了平衡。虽然依赖现有的交换机硬件限制了一定的灵活性,但 OpenFlow 几乎可以立即部署。
OpenFlow 交换机有一个包含数据包处理规则的表,每条规则都有一个模式(用于匹配数据包头中的比特)、一组动作(例如丢弃、泛洪、从特定接口转发、修改数据包头字段或将数据包发送至控制器)、计数器(用于跟踪字节数和数据包数)以及优先级(用于区分模式重叠的规则)。当接收到一个数据包时,OpenFlow 交换机会识别最高优先级的匹配规则,执行相关的动作并更新计数器
技术的推动和应用拉动:初始的 OpenFlow 协议通过构建在交换机已支持的技术基础上,实现了数据平面模型和控制平面 API 的标准化,在交换机上启用 OpenFlow 的初始功能就像进行固件升级一样简单,供应商无需升级硬件以使交换机具备 OpenFlow 功能。
OpenFlow 也开始在数据中心网络等领域中站稳脚跟,这些领域在大规模网络流量管理方面有着明确需求。在数据中心,雇用工程师编写复杂的控制程序以管理大量商用交换机的成本比持续购买那些无法支持新功能的封闭专有交换机要划算得多。随着供应商之间的竞争加剧,许多网络设备市场中的较小厂商抓住了通过支持 OpenFlow 等新功能与传统路由器和交换机厂商竞争的机会
知识贡献:
- 泛化网络设备和功能。 之前的路由控制研究主要集中在通过目标 IP 前缀匹配流量上。相较之下,OpenFlow 规则可以基于 13 种不同的数据包头字段定义转发行为。OpenFlow 在概念上统一了许多不同类型的网络设备,这些设备之间的差异仅在于它们匹配的头字段以及执行的操作。例如,路由器匹配目标 IP 前缀并转发到链路,而交换机则匹配源 MAC 地址(进行 MAC 学习)和目标 MAC 地址(执行转发),并可能泛洪或转发到单一链路。网络地址转换器和防火墙基于五元组(源和目标 IP 地址、端口号及传输协议)匹配,并进行地址和端口字段重写或丢弃不需要的流量。然而,OpenFlow 尚未为深度包检测或连接重组提供数据平面支持,因此单凭 OpenFlow 难以有效实现复杂的中间盒功能。
- 网络操作系统的愿景。 与先前的“主动网络”研究中提出的节点操作系统不同,OpenFlow 的工作带来了“网络操作系统” [37] 的概念。网络操作系统是一种将网络交换机中状态的安装与控制网络行为的逻辑和应用程序分离的软件。更广泛地说,网络操作系统的出现提供了网络操作的三层概念分解 [46]:1)具有开放接口的数据平面;2)负责维护网络状态一致性视图的状态管理层;3)根据网络状态视图执行各种操作的控制逻辑。
- 分布式状态管理技术。 控制平面和数据平面的分离带来了状态管理的新挑战。为了实现可扩展性、可靠性和性能,多控制器的运行至关重要,但这些副本应协同工作,使其行为如同一个逻辑上集中的控制器。早期关于分布式路由控制器的研究 [12, 81] 仅在路由计算的狭义上下文中解决了这些问题。为支持任意控制器应用,Onix [46] 控制器引入了“网络信息库”这一概念——一个由所有控制器副本共享的网络拓扑和其他控制状态的表示。Onix 还结合了分布式系统中的一些已有工作来满足状态一致性和持久性的需求。例如,Onix 采用了一个支持事务的持久数据库,通过一个分布式状态机来管理变化缓慢的网络状态,并使用一个内存中的分布式哈希表来管理一致性要求较弱的快速变化状态。
误解。 关于 SDN 的一个误解是每个流量的第一个数据包必须发送到控制器进行处理。事实上,一些早期系统(如 Ethane [16])确实采用了这种方式,因为它们设计用于小规模网络中的细粒度策略。实际上,SDN 和 OpenFlow 并不对规则的粒度或控制器是否处理任何数据流量做任何假设。
3. 网络虚拟化
在本节中,我们讨论网络虚拟化,这是SDN(软件定义网络)的一个早期重要“用例”。网络虚拟化提供了一种与底层物理设备解耦的网络抽象。它允许多个虚拟网络运行在一个共享的基础设施上,每个虚拟网络的拓扑可以比底层物理网络更加简化(更加抽象)。例如,虚拟局域网(VLAN)可以提供跨越多个物理子网的单一局域网的假象,多个VLAN可以在相同的交换机和路由器集合上运行。虽然网络虚拟化在概念上独立于SDN,但近年来这两项技术之间的关系变得更加密切。可编程网络通常假定了基础设施的共享机制(跨数据中心的多个租户、校园的管理群体或实验设施中的实验)和与物理网络不同的逻辑网络拓扑,这些都是网络虚拟化的核心原则。最后,我们提醒,"网络虚拟化"的精确定义难以界定。在本文中,我们将网络虚拟化的范围定义为任何支持在底层物理网络基础设施上托管虚拟网络的技术。
网络虚拟化与SDN的关系 网络虚拟化(物理网络的逻辑网络抽象)显然不需要SDN。同样,SDN(将逻辑上集中化的控制平面与底层数据平面分离)也不意味着网络虚拟化。然而,网络虚拟化与SDN之间出现了一种共生关系,催生了几个新的研究领域。SDN和网络虚拟化主要有以下三个方面的关系:
SDN作为网络虚拟化的使能技术。云计算推动了网络虚拟化的兴起,因为云提供商需要一种方法让多个客户(或“租户”)共享同一个网络基础设施。[Nicira](https://web.stanford.edu/class/ee204/2012/Nicira Networks.pdf)的网络虚拟化平台(NVP)提供了这一抽象,无需底层网络硬件的任何支持。该方案使用Overlay网络为每个租户提供一个连接其所有虚拟机的单一交换机的抽象。与以前的叠加网络不同,每个叠加节点实际上是物理网络的扩展——一个软件交换机(如Open vSwitch),用于封装发送到其他服务器上虚拟机的流量。一个逻辑上集中化的控制器在这些虚拟交换机中安装规则,控制数据包如何封装,并在虚拟机迁移到新位置时更新这些规则。
用于评估和测试SDN的网络虚拟化。SDN控制应用与底层数据平面解耦使得可以在虚拟环境中测试和评估SDN控制应用,然后再将其部署到运营网络。Mininet[41,48]使用基于进程的虚拟化运行多个虚拟OpenFlow交换机、终端主机和SDN控制器——每个在同一物理或虚拟机上作为单独的进程。进程虚拟化允许Mininet在单台机器上模拟拥有数百个主机和交换机的网络。在这种环境中,研究人员或网络操作员可以开发控制逻辑,并轻松在生产数据平面的完整仿真中测试它;一旦控制平面经过评估、测试和调试,就可以部署到实际生产网络。
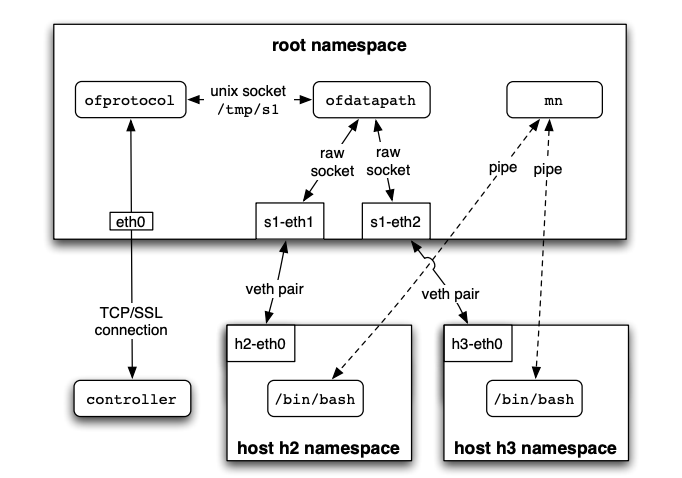
对SDN进行虚拟化。在传统网络中,虚拟化路由器或交换机很复杂,因为每个虚拟组件都需要运行自己的控制平面软件实例。相反,虚拟化一个“哑”SDN交换机要简单得多。FlowVisor[68]系统使校园可以在承载生产流量的同一物理设备上支持网络研究的测试平台。其主要思想是将流量空间划分为“切片”(PlanetLab[61]的早期工作引入的概念),每个切片拥有一部分网络资源,由不同的SDN控制器管理。FlowVisor作为一个管理程序运行,与各SDN控制器和底层交换机通过OpenFlow通信。
误解和误区 人们常常提到SDN的所谓“优势”——例如摊销物理资源成本或在多租户环境中动态重新配置网络——实际上来自网络虚拟化。虽然SDN促进了网络虚拟化,可能因此使实现这些功能更加容易,但需要认识到SDN提供的功能(即数据平面和控制平面的分离、分布式网络状态的抽象)并不直接提供这些好处。
4. 结论
随着SDN的持续发展,我们认为历史提供了重要的教训。首先,SDN技术的成败将取决于“使用驱动”。虽然SDN常被誉为解决所有网络问题的方案,但值得记住的是,SDN只是一个用来简化网络管理问题的工具。SDN仅仅是让我们能够开发新应用和解决长期存在的问题。在这一点上,我们的工作才刚刚开始。
其次,我们提醒,在愿景与务实之间的平衡依然脆弱。SDN的大胆愿景倡导了多种控制应用;然而,OpenFlow对数据平面的控制仅限于对包头字段的简单匹配-动作操作。我们应该记住,OpenFlow的初始设计是基于快速采用的需求,而非从第一原则出发。支持广泛的网络服务需要更复杂的流量分析和操作方式(例如深度包检测、压缩、加密和转码),这些可能需要使用商用服务器(如x86机器)或可编程硬件(如FPGA、网络处理器和GPU),或两者结合。有趣的是,最近对更复杂数据平面功能(如网络功能虚拟化)的兴趣,使我们回顾起早期主动网络的工作,完成了这一历史故事的回环。
保持SDN的大胆愿景要求我们继续“跳出框框”思考,寻找最佳的网络编程方式,而不被当前技术的局限性所束缚。我们不应仅仅根据当前的OpenFlow协议设计SDN应用,而应思考我们希望对数据平面有怎样的控制,并将这一愿景与务实的部署策略相结合。
论文阅读:B4——谷歌的SDWAN
B4: Experience with a Globally-Deployed Software Defined WAN, SIGCOMM'13
摘要
本文讲述B4的设计、实现和性能评估。 B4是连接谷歌全球数据中心的私有广域网(private WAN)。B4具有以下几个独特特点:i)巨大的带宽需求,但部署的站点数量适中;ii)弹性的流量需求,旨在最大化平均带宽;iii)对边缘服务器和网络的完全控制,使得可以在边缘进行流量限制和需求测量。这些特点促使采用基于软件定义网络(SDN)的架构,并由OpenFlow控制其中的交换机,这些交换机都是商用简单的。B4的集中式流量工程服务使链路接近100%的利用率,同时将应用流量分配到多个路径,以平衡带宽和应用优先级/需求。我们描述了B4在生产环境中运行三年的经验、所获得的教训以及未来的工作方向。
1. 引言
现代WAN对于互联网的性能和可靠性至关重要,它们通过成千上万个独立链路提供Tbps级别的总带宽。由于单个WAN链路成本高昂,并且WAN数据包丢失通常被视为不可接受,WAN路由器通常由高端、专业化的设备组成,这些设备强调高可用性。最后,WAN通常对所有bit进行无差别处理,所有应用通常都被平等对待,尽管它们对可用带宽的敏感性差异很大。
考虑到这些因素,WAN链路通常以30-40%的平均利用率进行配置。这使得网络服务提供商能够屏蔽几乎所有链路或路由器故障,用户几乎不受影响。但是成本代价也很大。
在构建一个连接多个数据中心、带宽需求巨大的WAN时,我们面临了这些开销。然而,谷歌的数据中心WAN展现出了一些独特的特点。首先,我们控制着应用、服务器以及整个LAN,直到网络的边缘。其次,我们带宽最密集的应用涉及大规模的数据复制,这些应用在高平均带宽的情况下表现最佳,并能根据可用带宽调整传输速率。它们也可以在故障或资源紧张期间让位于更高优先级的交互式应用。第三,我们预计数据中心的部署数量不会超过几十个,这使得对带宽进行集中控制成为可能。我们利用这些特性,采用了SDN架构的数据中心WAN互联。
我们的主要动机是部署定制的路由和流量工程协议,以满足我们的独特需求。我们的设计围绕以下几点展开:i)接受故障作为不可避免且常见的事件,其影响应暴露给最终应用程序;ii)交换机硬件提供一个简单的接口,以便在中央控制下编程转发表条目。网络协议可以在承载各种标准和定制协议的服务器上运行。我们的目标是,部署新型的路由、调度、监控和管理功能和协议既更简单,又能使网络更高效。
我们介绍了使用SDN原则和OpenFlow管理单个交换机来部署谷歌WAN B4的经验。特别是,我们讨论了如何同时支持标准路由协议和集中式流量工程(Traffic Engineer,TE),作为我们的第一个SDN应用。通过TE,我们:i)利用网络边缘的控制权,在资源受限时对竞争需求进行裁定;ii)使用多路径转发/隧道技术,根据应用优先级利用可用网络带宽;iii)在链路/交换机故障或应用需求变化的情况下,动态重新分配带宽。这些功能使得B4的许多链路能够接近100%的利用率运行,所有链路的平均利用率在较长时间内达到70%,相对于标准做法提高了2-3倍的效率。
B4已经部署了三年,目前承载的流量超过了谷歌面向公众的WAN,并且增长速度更快。它是最早和最大规模的SDN/OpenFlow部署之一。B4比传统方式更高效地满足了应用带宽需求,支持快速部署和迭代新型控制功能,如流量工程,并与最终应用紧密集成,以便在故障或通信模式变化时进行自适应调整。当然,SDN并非万能;我们总结了在大规模B4故障中的经验,指出了SDN和大规模网络管理中的挑战。虽然我们的方法并不适用于所有WAN或SDN,但我们希望我们的经验能为未来这两个领域的设计提供参考。
2. 背景
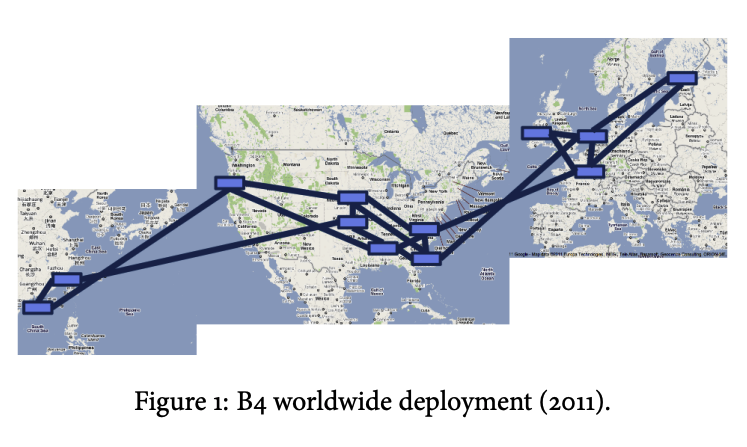
Google运营者两个独立广域网。其中B4专门负责数据中心之间的互联(如图1),例如支持异步数据拷贝、交互式服务系统的索引推送,以及为实现高可用性进行的终端用户数据复制。超过90%的内部应用流量经由该网络传输。另外一个是提供给用户的网络,更密集,主要为了在向终端用户交付内容时,必须保障最高级别的可用性。
B4承载着数千个独立应用,我们将其划分为三类:1)为实现高可用性/持久性将用户数据(如邮件、文档、音视频文件)复制到远程数据中心;2)为对固有分布式数据源进行计算而进行的远程存储访问;3)跨多数据中心同步状态的大规模数据推送。这三类流量按照体积递增、延迟敏感性递减、总体优先级递减的顺序排列。例如用户数据在B4中体积最小,但对延迟最敏感,且具有最高优先级。
下面是几个考量,
- 弹性带宽需求:我们数据中心的大部分流量涉及跨站点大型数据集同步。这类应用能够充分利用可用带宽,但也能容忍周期性故障导致的临时带宽降低。
- 有限站点数量:虽然B4需要在多个维度扩展,但由于面向数据中心部署,广域网站点总数控制在数十个量级。
- 终端应用控制权:我们同时掌控应用程序和接入B4的站点网络,因此可在网络边缘实施应用优先级管理和突发流量控制,而无需依赖过度配置或B4内部的复杂功能。
| 设计决策 | 设计原理/优势 | 面临的挑战 |
|---|---|---|
| 采用商用交换芯片构建B4路由器 | - B4应用愿用更高平均带宽换取容错性 - 边缘应用控制减少了对大缓冲区的需求 - 有限的B4站点意味着无需庞大转发表 - 较低的路由器成本助力网络容量扩展 | - 需牺牲硬件容错性、深度缓冲能力及大路由表支持 |
| 链路利用率提升至100% | - 高效利用昂贵的长途传输资源 - 多数应用愿用更高平均带宽换取可预测性 - 大带宽消费者能动态适配可用带宽 | - 链路/交换机故障时,严重容量损失导致丢包不可避免 |
| 集中式流量工程 | - 利用多路径转发在可用容量间平衡应用需求,以应对故障和需求变化 - 结合边缘速率限制,利用应用分类和优先级进行调度 - 传统分布式路由协议(如链路状态)的流量工程通常非最优 - 实现更快、确定的全局故障收敛 | - 缺乏现有协议支持该功能 - 需掌握站点间需求及业务重要性信息 |
| 硬件与软件解耦 | - 根据B4需求定制路由和监控协议 - 实现软件协议的快速迭代 - 通过外部复制更易防范常见软件故障 - 兼容所有导出相同编程接口的硬件部署 | - 开发模式未经实践检验 - 打破了硬件与软件间的命运共享机制 |
3. 设计
3.1 架构概述
我们的SDN架构可分为三层(图2)。B4服务多个广域网站点,每个站点包含若干服务器集群。在B4站点内:交换机硬件层主要负责流量转发,不运行复杂控制软件;站点控制层由网络控制服务器(NCS)构成,承载OpenFlow控制器(OFC)和网络控制应用(NCA)。
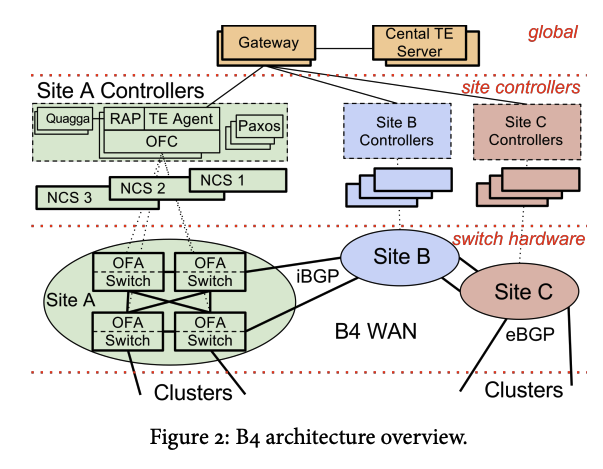
这些服务器通过Routing overlay实现分布式路由与集中流量工程。OpenFlow控制器(OFC)根据网络控制应用(Network Controller Application, NCA)的指令和交换机事件维护网络状态,并基于动态变化的网络状态指导交换机设置转发表项。为实现单服务器与控制进程的容错,每个站点通过Paxos算法[9]从部署在不同物理服务器上的多个软件副本中选举主实例。
Global层由逻辑上集中的应用(如SDN网关和中心化流量工程服务器)构成,通过站点级NCA实现对全网的集中控制。SDN网关向中央流量工程服务器屏蔽OpenFlow协议和交换机硬件的实现细节。我们将Global层应用复制到多个广域网站点,并通过独立的主节点选举机制确定主实例。
网络中每个服务器集群都是一个逻辑"自治系统"(AS),拥有特定IP前缀集。每个集群包含一组BGP路由器(图2未显示),它们与各广域网站点的B4交换机建立对等连接。早在引入SDN之前,我们就将B4作为单一AS运行,在为运行传统BGP/ISIS网络协议的集群间提供中转服务。选择BGP是因其具备域间隔离特性且运维人员熟悉该协议。基于SDN的B4必须支持现有分布式路由协议,既要与非SDN广域网实现互操作,也要支持渐进式部署。
我们考虑了多种现有路由协议与集中流量工程的集成方案。激进方案是构建融合路由(如ISIS功能)与流量工程的一体化集中服务。但我们最终选择将路由和流量工程作为独立服务部署:先部署标准路由服务,再以覆盖层形式部署集中流量工程。这种分离带来多重优势:初期可专注于SDN基础设施构建(如OFC、代理、路由等);由于初始部署时不包含流量工程等新外部功能,为后续开发调试SDN架构预留了时间。
最关键的是,我们通过优先级转发表项(§5)在基础路由协议之上分层实现流量工程。这种隔离机制为网络提供了"紧急开关":当流量工程出现严重问题时,可立即禁用该服务并回退到最短路径转发。这种故障恢复机制已被证明极具价值(§6)。
每个B4站点包含多台交换机,可能通过数百个物理端口连接远程站点。为提升可扩展性,流量工程将每个站点抽象为单一节点,与各远程站点间仅保留单条容量聚合的虚拟边。为实现这种拓扑抽象,所有跨站点流量必须均匀分布在其所有物理链路上。B4路由器采用定制化的ECMP哈希算法[37]实现必要的负载均衡。
本节后续将阐述如何在支持OpenFlow的硬件交换机上,与独立控制服务器运行的现有路由协议进行集成。第4章则介绍如何在此基础路由实现之上构建流量工程层。