Lec 7 数据中心网络架构
十几年前,谷歌发现传统的网络架构无论是硬件还是软件,都无法满足其带宽需求和数据中心分布式计算基础设施的规模。秉着 “没有人做就自己做” 的精神,谷歌开始构建自己的网络硬件和软件,将数据中心中所有的服务器连接在一起,为其分布式计算和存储系统提供动力。
2015年,谷歌在SIGCOMM会议上发表论文《Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network》,详细地阐述了谷歌过去多年在数据中心网络的创新和演进。
该论文写道:“我们意识到现有的商业解决方案无法满足我们的规模、管理和成本要求。因此,我们决定构建自己的定制数据中心网络硬件和软件,可以通过Clos 拓扑和当时新兴(约 2003 年)的商业交换芯片将集群结构扩展到任意大小。”
此后,谷歌开始了自研之旅。2005年,谷歌设计了第一代数据中心网络,名为Firehose 1.0。一年后,第二代Fierhose 1.1并真正部署在了谷歌数据中心的网络中。随后,第三代Watchtower、第四代Saturn被推出。2012年,谷歌第五代数据中心网络Jupiter引入了SDN技术并且使用了OpenFlow
- A. Greenberg et al., VL2: A Scalable and Flexible Data Center Network, SIGCOMM 2009.
- (Optional) A. Singh et al., Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network, SIGCOMM 2015
斯坦福阅读资料
Fat-tree: A Scalable, Commodity Data Center Network Architecture
Al-Fares et al.
SIGCOMM 2008
Jupiter Evolving: Transforming Google's Datacenter Network via Optical Circuit Switches and Software-Defined Networking
Poutievski et al.
SIGCOMM 2022
数据中心的需求与广域网相反:拓扑规则、由单一机构控制,目标是用廉价商用交换机 (commodity switches) 提供满二分带宽 (full bisection bandwidth)。
5.1 Fat-Tree:用商用交换机做无收敛网络
Al-Fares et al., A Scalable, Commodity Data Center Network Architecture (SIGCOMM 2008)。传统三层树形拓扑在核心层超额订阅 (oversubscription),且依赖昂贵的高端核心交换机。
用全同的 k 端口交换机构造的特殊 Clos 拓扑:分 k 个 pod,每个 pod 含 k/2 个边缘交换机与 k/2 个汇聚交换机,核心层有 $(k/2)^2$ 台交换机。可接入主机数为 $$N = \frac{k^3}{4}$$ 理论上提供 1:1 满二分带宽。
取 48 端口商用交换机:可接入主机 $$N = \frac{48^3}{4} = \frac{110592}{4} = 27648\ \text{台}$$ 核心交换机 $(48/2)^2 = 576$ 台。全程仅用同一档廉价交换机即可达成满二分带宽,这是该论文相对传统设计的核心成本优势。
路由上,Fat-Tree 用两级路由表与特制地址编码,把流量在多条等价路径上铺开,避免热点。
5.2 VL2:敏捷性与流量随机化
Greenberg et al., VL2: A Scalable and Flexible Data Center Network (SIGCOMM 2009)。三大目标:均匀高容量、性能隔离、敏捷性 (agility,任意服务器可分配给任意服务)。
两项关键技术:
- 名址分离:应用地址 (AA, Application Address) 与位置地址 (LA, Locator Address) 解耦,由目录系统 (directory system) 做映射——服务器可随意迁移而 IP 不变,实现敏捷性。
- VLB 流量随机化:在 Clos 拓扑上结合 ECMP 与阀门负载均衡 (Valiant Load Balancing, VLB),把每条流先随机送到一个中间交换机再转发,使任意流量矩阵下链路负载趋于均匀。
Fat-Tree 解决"拓扑层面"如何便宜地造出满带宽;VL2 解决"如何把这条带宽真正用满且隔离"——靠流量随机化对抗突发的流量矩阵,靠名址分离换取调度自由。二者常被组合理解为数据中心 fabric 的"硬件 + 软件"两面。
5.3 Jupiter(选读):十年 Clos 与集中控制
Singh et al., Jupiter Rising (SIGCOMM 2015) 回顾 Google 数据中心网络十年演进(Firehose → Watchtower → Saturn → Jupiter),三条主线:坚持 Clos 拓扑、采用商用芯片 (merchant silicon)、用集中式控制 (centralized control,Firepath) 取代传统分布式协议。Jupiter 已达建筑级 fabric、超 1 Pbps 二分带宽,印证了"集中控制 + 规则拓扑"在受控环境下的可扩展性(呼应 Lec 8 的 SDN)。
论文阅读: 微软的VL2 数据中心网络
摘要
为了实现灵活且具成本效益的数据中心,数据中心应能够在大型服务器池中动态分配资源。特别是,数据中心网络应支持将任意服务器分配给任意服务。为实现这些目标,我们提出了VL2,一种能够在大型数据中心中扩展的实用网络架构,具备服务器间的高带宽、服务间的性能隔离以及以太网二层语义。VL2采用以下技术:(1) 扁平地址分配,使服务实例可以被部署在网络中的任意位置;(2) 瓦良特负载均衡(Valiant Load Balancing),能够将流量均匀地分散到各个网络路径上;(3) 基于终端系统的地址解析,以支持大型服务器池的扩展,且不增加网络控制平面的复杂度。VL2的设计基于对大型云服务提供商的流量和故障数据的详细测量。VL2的实现利用了已有的成熟网络技术,这些技术已在高速硬件中实现且成本低廉,从而构建出可扩展、可靠的网络架构。由于此设计,VL2网络现已可以投入部署,我们也构建了一个工作原型。我们通过测量、分析和实验对VL2设计的优点进行了评估。我们的VL2原型在395秒内在75台服务器间传输了2.7 TB数据——达到了可能最大速率的94%
1. 介绍
为了盈利,这些数据中心必须实现高效利用,而关键在于灵活性——即能够将任何服务器分配给任何服务的能力。灵活性带来了风险管理的改进和成本的节约。如果没有灵活性,每个服务都必须预先分配足够的服务器,以应对难以预测的需求高峰,否则就有可能在需求骤增时无法满足需求而导致失败。而有了灵活性,数据中心运营商可以从一个大型共享服务器池中满足个别服务的波动需求,从而提高服务器利用率并降低成本。
然而,当今数据中心的网络设计在多个方面阻碍了这种灵活性。
首先,现有架构未能提供足够的服务器间通信带宽。传统架构依赖于由高成本硬件构建的树状网络配置。由于设备成本高昂,在数据中心的树状网络架构中,不同分支之间的带宽通常被超额分配,比例为1:5或更高,这意味着下层网络的带宽总需求远高于上层连接实际提供的带宽。特别是在树状结构的最高层,带宽超额分配比例更高,通常为1:80至1:240。这限制了服务器之间的通信,导致服务器池分散——即使其他地方有空余带宽,也会出现拥塞和计算热点的情况。
其次,尽管数据中心托管多个服务,但网络在防止一个服务的流量泛滥影响其他服务方面几乎没有提供帮助——当某个服务出现流量泛滥时,与其共享相同网络子树的所有服务往往会受到波及。
第三,传统网络的路由设计通过为服务器分配与拓扑相关的IP地址并将服务器划分为VLAN来实现扩展。这种地址空间的分割限制了虚拟机的迁移能力,虚拟机无法在保持原有IP地址的情况下迁出其原始VLAN。此外,地址空间的分割在服务器重新分配时带来了大量配置负担,通常需要人工干预,从而限制了部署速度。
为了克服现有设计的局限性并实现敏捷性,我们让每个服务拥有这样的“幻觉”:所有分配给它的服务器(且仅限这些服务器)都像是由一个单独、不受干扰的以太网交换机(即虚拟层2 Virtual Layer 2)连接在一起,并且在每个服务规模从1台服务器扩大到10万台服务器的情况下,仍然保持这种幻觉。实现这一愿景,具体需要构建一个符合以下三项目标的网络:
- 统一的高容量:服务器之间的通信速率仅受发送和接收服务器的网络接口卡所能提供的容量限制,而服务器的分配与网络拓扑无关。
- 性能隔离:一个服务的流量不应影响到其他服务的流量,就像每个服务都由一个单独的物理交换机连接一样
- 提供2层语义:就像在局域网中一样——由于扁平化地址机制,任何IP地址都可以连接到以太网交换机的任意端口——数据中心的管理软件应该能够轻松地将任何服务器分配给任何服务,并为该服务器配置服务所需的任意IP地址。虚拟机应能够迁移到任意服务器并保持相同的IP地址,每个服务器的网络配置应与通过局域网连接的情况一致。最后,许多遗留应用程序依赖的链路本地广播等功能应能够正常工作。
然而,数据中心服务器上的软件和操作系统已经被广泛修改(如为虚拟化创建了Supervisor或用来存储数据的Blob文件系统)。因此,VL2的设计探索了主机和网络之间的新职责分工——使用2.5层的一个附加层在服务器的网络栈中,以绕过网络设备的限制。不需要任何新的交换机软件或API
VL2由使用低成本交换机ASIC构建的网络组成,安排成Clos拓扑结构,提供服务器之间的广泛路径多样性。我们的测量显示,数据中心的工作负载、流量和故障模式具有极大的波动性。为应对这种波动性,我们采用了Valiant负载平衡(VLB),以在所有可用路径上均匀分布流量,而无需集中协调或流量工程。使用VLB,每个服务器为其发送到数据中心中其他服务器的每个数据流独立选择一条随机路径。人们普遍担心VLB会引入额外的延迟和消耗额外的网络容量,因为路径延长的问题,但我们环境(数据中心内部传播延迟非常小)和拓扑结构(包括一个用于数据包跳转的额外交换层)结合,解决了这些问题
构成网络的交换机作为层3路由器运行,使用OSPF计算路由表,从而实现了多路径使用(不像生成树协议)且使用了一个备受信任的协议。然而,数据中心运行的服务使用的IP地址不能与网络中的特定交换机绑定,否则服务器之间的重新分配能力将会丧失。借助于许多系统中使用的一个技巧,VL2为服务器分配的IP地址仅作为名称使用,没有任何拓扑意义。当一台服务器发送数据包时,服务器上的附加层在目录系统中查询目的地的实际位置,然后将原始数据包封装发送到该位置。附加层还帮助消除了层2网络中由ARP引起的可扩展性问题,并且封装操作提升了我们实施VLB的能力。这些设计特点使VL2在提供层2语义的同时,消除了现有架构中由于地址和位置绑定所导致的服务器池容量分散和浪费。
总之,VL2在拓扑、路由设计和软件架构上的选择创造了一个巨大的共享网络容量池,每对服务器都可以在通信时从中获得带宽。我们通过在Clos拓扑结构的顶层随机选择一台交换机进行跳转来实现VLB,并利用层3路由器的特性(如等价多路径)在两个路径段上分布流量。此外,我们使用任播地址和Paxos协议的实现,使得目录系统的设计简化,同时在发生故障时提供与现有协议相当的一致性属性。
我们设计的可行性取决于几个实验性验证的问题。首先,Valiant负载平衡的理论表明网络将无热点,并要求(a)随机化在小数据包粒度上进行,且(b)进入网络的流量符合管道模型。然而,由于实际原因,VL2为每个流选择不同的路径,而不是每个数据包,并依赖TCP来控制进入管道模型的流量。尽管如此,我们的实验表明,对于数据中心流量,VL2的设计选择足以在实际部署中实现所需的无热点属性。其次,提供数据中心服务器路由信息的目录系统必须能够以非常低的延迟处理高负载。我们证明了设计和实现这样的目录系统是可行的。
在本文的其余部分,我们将大致按以下顺序进行贡献:
- 我们首次对生产数据中心的流量模式进行了研究,发现流量波动性极大,在一天中循环出现50-60种不同的模式,并且在60%分位数上每种模式的持续时间少于100秒。
- 我们在一个由80台服务器组成的集群中设计、构建并部署了VL2的所有组件,并通过实验验证了VL2实现了目标的特性,如统一的容量和性能隔离。我们还展示了网络的速度,例如在395秒内在75台服务器之间传输2.7 TB数据的能力。
- 我们在数据中心的交换结构中应用了Valiant负载平衡,展示了流量级流量分流在现实数据中心流量中实现了几乎相同的分流比例(分流公正性指数在1%之内),并平滑了利用率,消除了持续拥堵。
- 我们通过与现有设计的等效网络进行成本比较,证明了VL2网络的设计权衡。
4. 虚拟2层网络
4.2 VL2 地址寻址与路由
本节解释数据包如何在VL2网络中流动,以及拓扑结构,路由设计,VL2代理和目录系统如何结合起来对底层网络结构进行虚拟化——创造出主机连接到一个大型、非干扰性的数据中心广域二层交换机的错觉。
4.2.1 地址解析和数据包转发
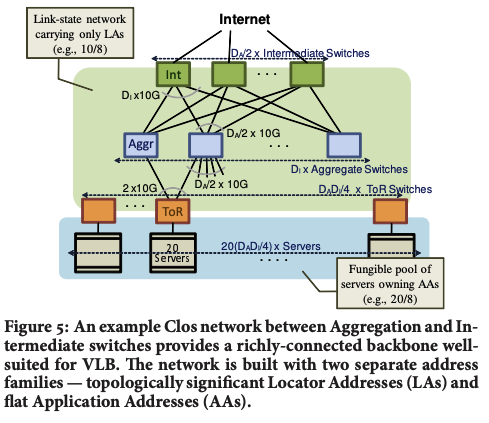
VL2 使用两种不同的IP地址族,如图6所示。网络基础设施使用位置特定(location-specific)的IP地址(LAs);所有交换机和接口都分配有LAs,交换机运行基于IP的(第三层)链路状态路由协议,仅传播这些LAs。这使得交换机能够获取完整的交换机级拓扑结构,并沿最短路径转发带有LAs的数据包。另一方面,应用程序使用应用特定(application-specific)的IP地址(AAs),这些地址在服务器因虚拟机迁移或重新配置而改变位置时保持不变。每个AA(服务器)与一个LA关联,该LA是ToR交换机的标识符,VL2目录系统存储AA与LA之间的映射,这个映射在应用服务器被配置到某项服务并分配AA地址时创建。
提供二层语义的关键在于使服务器相信它们与同一服务中的其他服务器共享一个大的IP子网(即,整个AA空间),同时消除困扰大型以太网的ARP和DHCP扩展瓶颈。
数据包转发: 为了在使用AA地址的服务器之间路由流量,而底层网络了解LA地址的路由,VL2代理在每个服务器上拦截来自主机的数据包,并使用目标ToR的LA地址对数据包进行封装,如图6所示。一旦数据包到达LA(目标ToR),交换机解封装数据包并将其发送到内部头中携带的目标AA
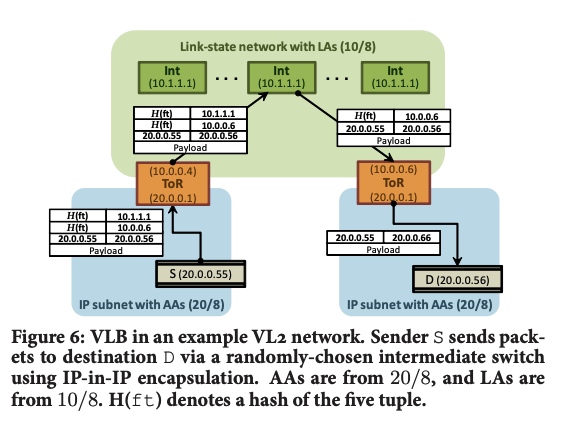
地址解析:因此,当一个应用程序首次向AA发送数据包时,主机上的网络栈会生成一个针对目标AA的广播ARP请求。运行在主机上的VL2代理拦截此ARP请求,并将其转换为对VL2目录系统的单播查询。目录系统回答查询,并提供应将数据包隧道化的ToR的LA。VL2代理缓存这个AA到LA地址的映射,类似于主机的ARP缓存,以便后续通信无需进行目录查找
通过目录服务进行访问控制:如果目录服务拒绝提供一个LA供其路由数据包,服务器则无法向AA发送数据包。这意味着目录服务可以执行访问控制策略。此外,由于目录系统在处理查找请求时知道哪个服务器在发起请求,因此可以执行细粒度的隔离策略。例如,它可以实施仅允许同一服务的服务器之间通信的策略。VL2的一个优点是,当允许服务之间的通信时,数据包可以直接从源发送到目的地,而无需像传统架构中连接两个VLAN时那样绕行到IP网关。
选择这些寻址和转发机制有两个原因。首先,它们使得能够使用低成本的交换机,这些交换机通常具有较小的路由表(通常只有16K条目),只能容纳LA路由,而不必担心大量的AA。其次,它们减少了网络控制平面的开销,防止其看到主机状态的变动,而是将这项任务交给更具可扩展性的目录系统。
论文阅读: 谷歌数据中心网络中的十年Clos拓扑和集中控制
摘要
我们提出了一种解决十年前数据中心网络普遍存在的成本、操作复杂性和规模有限的问题的方法。本文用3个主题来统一详细描述5代数据中心。
- 使用标准交换机的多级Clos拓扑是搭建大规模建筑网络的一种经济有效的方法
- 复杂的去中心化路由和管理协议对于我们的单一运营商数据中心网络来说是不必要的,因此我们创建了一个集中控制系统,向所有交换机发送全局配置
- 我们的模块化硬件设计和简单的软件还支持集群间和广域网络
在过去十年中,我们的数据中心网络已扩展到全球多个地点,容量增加了100倍
1. 引言
数据中心网络是云计算的关键推动力。数据中心的带宽需求每12至15个月翻一番(见图1),增长速度甚至超过广域互联网。一些近期趋势推动了这一增长。数据集的规模正在不断扩大,越来越多的照片/视频内容、日志和互联网连接传感器的激增。