Lec 12 语法 & 解析
完成本节学习,应掌握:
- 理解语法生成式和正则表达式运算符的概念
- 能够阅读一个语法或正则表达式,并判断它是否能匹配某个字符序列
- 能够编写一个语法或正则表达式,用于匹配一组字符序列
- 能够结合语法和解析器生成器,将字符序列解析成语法树
- 能够将语法树转换为有用的数据类型
介绍
阅读内容介绍了几个概念:
- 文法(aka 语法,grammars):包括产生式(productions)、非终结符(nonterminals)、终结符(terminals)和运算符(operators)
- 正则表达式(regular expressions)
- 解析生成器(parser generators)
就像我们之前讨论过的那些有多个客户端和多种实现的模块一样,不同用户之间需要共享对这种字符串或流的格式约定。换句话说,这种序列需要一个规范(specification)来定义它的结构。
- 一个字符串
- 磁盘的一个文件,此时规范被称为文件格式(file format)
- 通过网络发送的消息,此时规范被称为网络协议(wire protocol)
- 用户在控制台上输入的命令,此时规范被称为命令行接口(command line interface)
对于这些序列,我们引入了语法的概念,它不仅使我们能够区分合法和非法序列,还能将序列解析为程序可以使用的数据结构。
这种由文法生成的数据结构通常是递归数据类型,就像我们在“递归数据类型”那一节中讨论过的那样。
此外,我们还将学习一种文法的特殊形式——正则表达式。正则表达式除了可以用来描述规范和解析字符串外,还是一种被广泛使用的字符串处理工具, 常用于分解字符串、提取信息或进行文本转换。
最后,我们会介绍语法分析器生成器(parser generator), 这是一种可以根据文法自动生成对应解析器的工具。
语法
为了描述一个符号串——无论这些符号是字节、字符,还是其他来自固定集合的符号——我们使用一种紧凑的表示方法,称为语法(grammar)。
语法定义了一组字符串,通常称为一种语言(language)。为了介绍语法的概念,本文将以表示 URL 的语法为例。我们的 URL 语法将规定在 HTTP 协议中哪些字符串是合法的 URL。
语法由两种主要元素组成:终结符(terminals)和非终结符(nonterminals)。
语法中的字面字符串称为终结符。之所以叫终结符,是因为它们无法再被进一步展开。我们通常用引号来表示终结符,例如 'http' 或 ':'。
相对地,非终结符可以看作变量,它们可以匹配一组可能的字符串,因此可以继续展开。那么如何决定非终结符可以取哪些值呢?
每个语法都由一组产生式(productions)或规则(rules)组成,每个产生式通过其他非终结符、运算符和终结符来定义一个非终结符。语法中的产生式一般具有如下形式:
nonterminal ::= terminals、nonterminals and operators语法中的某个非终结符被指定为根(root)。按照惯例,我们通常把根的产生式放在最前面,以方便人类理解。语法所能识别的字符串集合,就是那些能与根非终结符匹配的字符串。这个非终结符有时也被称为 root、start 或 S,但在下面的语法中,我们会使用更具可读性的名字,如 url、html、markdown 等。
例如,一个只允许单个特定URL的语法(即只包含一个字符串的集合)肯呢个只有一个产生式:
url ::= 'http://mit.edu'语法操作符
产生式可以在右侧使用运算符来组合终结符和非终结符。三种最重要的运算符是:
- 重复(Repetition),用 * 表示。 例如,
x ::= y*表示 x 可以匹配零个或多个 y - 连接(Concatenation),没有符号表示,仅用空格区分。 例如,
x ::= y z表示 x 匹配 y 后面紧跟 z - 并集或交替(Union / Alternation),用 | 表示:例如
x ::= y | z表示 x 匹配 y 或 z
按照惯例,后缀运算符(如 *)的优先级最高,其次是连接,最后是交替(|)。括号可以用来改变优先级。
我们用这些运算符来扩展前面的 URL 语法,使其能匹配更多主机名,如 http://stanford.edu/ 和 http://google.com/:
url ::= 'http://' hostname '/'
hostname ::= 'mit.edu' | 'stanford.edu' | 'google.com'第一条规则展示了连接运算。url 非终结符匹配的字符串由三部分组成:以 'http://' 开头,接着匹配 hostname 非终结符,最后是 '/'。
hostname 规则展示了交替运算。hostname 可以匹配三种字符串中的任意一种:'mit.edu'、'stanford.edu' 或 'google.com'。
接下来,我们再进一步,使语法能匹配任意由小写字母组成的主机名部分,例如 mit、stanford、google、com、edu 等:
url ::= 'http://' hostname '/'
hostname ::= word '.' word
word ::= letter*
letter ::= ('a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 'h' | 'i'
| 'j' | 'k' | 'l' | 'm' | 'n' | 'o' | 'p' | 'q'
| 'r' | 's' | 't' | 'u' | 'v' | 'w' | 'x' | 'y' | 'z')新的 word 规则匹配由零个或多个小写字母组成的字符串,因此整个语法现在可以匹配, 例如, http://alibaba.com/ 和 http://zyxw.edu/ 等 URL。不过,word 也可以匹配空字符串,这导致该语法还会错误地匹配 http://./,这不是合法的。为了解决这个问题,我们可以强制要求word至少包含一个字母:
word ::= letter letter*更多语法操作符
你还可以使用一些额外的运算符,它们只是语法糖(即:等价于前面三种主要运算符的某种组合)。
- 可选出现(0 次或 1 次)用
?表示。x ::= y?表示可以是一个y,也可以是空字符串 - 出现一次或多次用
+表示,x ::= y+表示x是一个或多个y,等价于x ::= y y* - 指定确切出现次数或出现次数范围可以用
{n}、{n,m}、{n,}或{,m}表示:x ::= y{3}表示x是3个y, 等价于x ::= y y yx ::= y{,4}表示 x 是至多 4 个 y, 等价于x ::= | y | y y | y y y | y y y y
- 字符类
[ ... ]表示匹配方括号中任意一个字符的单字符字符串集合x ::= [aeiou]等价于:x ::= 'a' | 'e' | 'i' | 'o' | 'u'
- 可以用
-来紧凑地表示字符范围:x ::= [a-ckx-z]等价于:x ::= 'a' | 'b' | 'c' | 'k' | 'x' | 'y' | 'z'
- 反向字符类
[^ ... ]表示匹配不在方括号内列出的任意单个字符x ::= [^a-c],即所有不在 a-c 范围内的字符, 等价于:x ::= 'd' | 'e' | 'f' | ... | '0' | '1' | ... | '!' | '@'
借助这些附加运算符,我们可以更简洁地定义前面的 word 产生式:
url ::= 'http://' hostname (':' port)? '/'
hostname ::= word '.' hostname | word '.' word
port ::= [0-9]+
word ::= [a-z]+语法中的递归
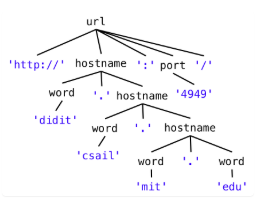
我们还需要进一步泛化。主机名可能包含两个以上的部分,也可能带有可选的端口号,例如:http://didit.csail.mit.edu:4949/
要处理这种字符串,语法可以写成:
url ::= 'http://' hostname (':' port)? '/'
hostname ::= word '.' hostname | word '.' word
port ::= [0-9]+
word ::= [a-z]+注意 hostname 的定义是递归的。思考一下,定义中哪一部分是基本情况(base case),哪一部分是递归步骤(recursive step)?这种定义允许哪些主机名?
使用重复运算符,我们也可以不用递归写出 hostname:
hostname ::= (word '.')+ word解析语法树
将语法与字符串进行匹配时,可以生成一棵解析语法树(简称语法树),用于展示字符串的各个部分是如何对应到语法中的各个部分的。
语法树的叶节点带有终结符标签,表示字符串中被解析出来的具体部分。这些叶节点没有子节点,也无法再被展开。如果按照顺序将所有叶节点的内容连接起来,就能重新得到原始字符串。 一个简单的例子是我们最初那个只有一行定义的 URL 语法,它唯一可能的语法树如下图所示。
语法树的内部节点带有非终结符标签,因为它们都有子节点。 一个非终结符节点的直接子节点必须遵循语法中该非终结符的产生式规则。例如,在我们较为复杂的 URL 语法中,hostname 节点的子节点必须符合规则 hostname ::= word '.' word 的结构。
再进一步看递归定义的 URL 语法,它生成的语法树结构更加丰富。在这棵树中,hostname 和 word 等非终结符节点的子树分别对应于语法中它们自己的定义规则。
例子: Markdown和HTML
为了简化起见,我们的示例语法只描述斜体(italic),
在markdown下
这是 _斜体_在html下
这是 <i>斜体</i>下面是我们简化版的 Markdown 语法:
markdown ::= ( normal | italic )*
italic ::= '_' normal '_'
normal ::= text
text ::= [^_]*再看我们简化版的 HTML 语法:
html ::= ( normal | italic )*
italic ::= '<i>' html '</i>'
normal ::= text
text ::= [^<>]*正则表达式
正则语法有一个特殊性质: 通过将每个非终结符(除了根非终结符)替换为其右侧表达式,可以将整个语法化简为只有根非终结符的一条产生式,右侧只包含终结符和操作符。
我们的 URL 语法就是正则语法。通过替换非终结符,它可以化简为一条表达式:
url ::= 'http://'([a-z]+ '.')+ [a-z]+ (':' [0-9]+)? '/'Markdown 语法也是正则语法:
markdown ::= ([^_]* | '_' [^_]* '_' )*但是 HTML 语法无法完全化简。即使将非终结符替换为其右侧表达式,最终也只能化简为:
html ::= ( [^<>]* | '<i>' html '</i>' )*不幸的是,右侧递归使用的 html 无法消除,也不能简单地用重复操作符代替,所以 HTML 语法不是正则语法。
终结符和操作符化简后的表达式可以写成更紧凑的形式,称为正则表达式(regular expression)。正则表达式去掉了终结符的引号以及终结符和操作符之间的空格,仅由终结符字符、用于分组的括号和操作符组成。例如,Markdown 的正则表达式就是:
([^_]*|_[^_]*_)*正则表达式也简称为 regex。相比原始语法,regex 可读性较差,因为缺少非终结符名称来说明子表达式的含义。但许多编程语言提供了对 regex 的库支持(而对语法本身通常没有),并且 regex 的匹配速度远快于语法解析。
在编程语言库中常见的正则表达式语法还包括一些额外的特殊字符,例如:
.匹配任意单个字符(有时不包括换行符,取决于库)\d匹配任意数字字符,相当于[0-9]\s匹配任意空白字符,包括空格、制表符、换行符\w匹配任意单词字符,包括下划线,相当于[a-zA-Z_0-9]
反斜杠 \ 也用于转义操作符或特殊字符,使其按字面值匹配。常见需要转义的特殊字符包括:
\. \( \) \* \+ \| \[ \] \\另一种转义特殊字符的方法是将其放在字符类方括号 [...] 内,例如 [.] 也可以匹配字面上的 .。在字符类中,大多数特殊字符会失去特殊含义,但像 [, ], ^, -, \ 仍需用反斜杠转义
正则表达式实际运用
在 TypeScript/JavaScript 中,可以用正则表达式操作字符串。现代脚本语言如 Python、Ruby 也原生支持 regex,并可在文本编辑器中用于查找替换。
在某些语言中(如 TypeScript/JavaScript),regex 有自己的字面量语法,用斜杠 /…/ 包裹。在其他语言(如 Python、Java)中没有特殊语法,只能使用字符串。