Lec 11 递归数据类型
本节我们将探讨递归定义的类型、如何指定此类类型的操作以及如何实现它们。我们的主要示例是immutable lists。
完成本节学习,应掌握:
- 理解递归数据类型
- 读写数据类型定义
- 理解并实现递归数据类型函数
- 理解immutable lists并了解其标准操作
- 了解并遵循使用ADT编写程序的规则
递归
在介绍递归数据类型之前,我们回顾一下递归函数,在6.010学习中,我们知道,
- 递归 讨论了基本情况(base case)和递归情况(recursive case),介绍了递归辅助函数,并展示了如何用递归实现多个函数。
- 递归与迭代 这部分讨论了递归(函数调用自身)和迭代(循环)之间的在表达重复计算时的对偶关系。还介绍了递归计算的三种常见模式:链表型(list-like)、树型(tree-like)和图型(graph-like)。在接下来的内容中,链表式和树状递归模式将特别重要。
正如递归函数是通过自身定义的,递归数据类型也是通过自身来定义的。我们同样会看到基本情况和递归情况的需求,只不过现在它们会体现在抽象类型的不同变体上。
示例:不可变链表
不可变性(immutability)的强大之处不仅在于它的安全性,还在于它允许共享。共享带来的实际的性能好处:占用更少的内存、减少拷贝开销。
我们定义一个不可变链表类型ImList<Element>,它有四种基本操作:
empty: void → ImList // 返回一个空链表
cons: Element × ImList → ImList // 将一个元素加到另一个链表的头部,返回新的链表
first: ImList → Element // 返回链表的第一个元素(要求链表非空)
rest: ImList → ImList // 返回除第一个元素外的子链表(要求链表非空)这四个操作历史悠久,来源于早期的 Lisp 和 Scheme 语言(在那里面,它们分别叫做 nil, cons, car, 和 cdr)。在函数式编程中,first 和 rest 有时也被称为 head 和 tail。
我们用方括号表示链表,如 [1, 2, 3],并把操作写成函数形式:
empty() → [ ]
cons(0, empty()) → [0]
cons(0, cons(1, cons(2, empty()))) → [0, 1, 2]
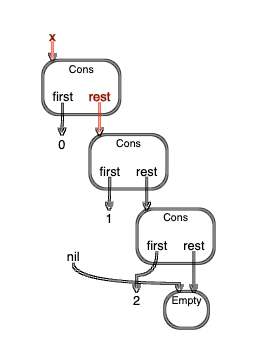
x = cons(0, cons(1, cons(2, empty()))) → [0, 1, 2]
first(x) → 0
rest(x) → [1, 2]
first(rest(x)) → 1
rest(rest(x)) → [2]
first(rest(rest(x))) → 2
rest(rest(rest(x))) → [ ]first、rest、cons 三者的基本关系是:
first(cons(x, y)) = x
rest(cons(x, y)) = y也就是说:cons 负责组合,而 first 与 rest 负责拆解。
TypeScript 中的不可变链表
我们用一个接口来定义这个ADT:
interface ImList<Element> {
cons(first: Element): ImList<Element>;
readonly first: Element;
readonly rest: ImList<Element>;
}两个实现类, 我们用两个类实现该接口:
Empty表示空链表(empty()的结果)Cons表示非空链表(cons()的结果)
class Empty<Element> implements ImList<Element> {
public constructor() {
}
public cons(first: Element): ImList<Element> {
return new Cons<Element>(first, this);
}
public get first(): Element {
throw new Error("unsupported operation");
}
public get rest(): ImList<Element> {
throw new Error("unsupported operation");
}
}这里使用了 getter 方法,让在空链表上访问 first 或 rest 时能立即报错。
接下来是 Cons 类:
class Cons<Element> implements ImList<Element> {
public readonly first: Element;
public readonly rest: ImList<Element>;
public constructor(first: Element, rest: ImList<Element>) {
this.first = first;
this.rest = rest;
}
public cons(first: Element): ImList<Element> {
return new Cons<Element>(first, this);
}
}已经实现了 cons,first, rest三个操作,那empty怎么办呢?
工厂函数实现empty(), 一个做法是让调用者直接创建new Empty(),但这样暴露了具体实现类,不符合ADT的封装原则,更好的方法是定义一个工厂函数
function empty<Element>(): ImList<Element> {
return new Empty<Element>();
}
实际使用示例
| TypeScript 语法 | 函数式写法 | 结果 |
|---|---|---|
const nil: ImList<number> = empty(); | nil = empty() | [ ] |
nil.cons(0) | cons(0, nil) | [0] |
nil.cons(2).cons(1).cons(0) | cons(0, cons(1, cons(2, nil))) | [0, 1, 2] |
const x = nil.cons(2).cons(1).cons(0); | x = cons(0, cons(1, cons(2, nil))) | [0, 1, 2] |
x.first | first(x) | 0 |
x.rest | rest(x) | [1, 2] |
x.rest.first | first(rest(x)) | 1 |
x.rest.rest | rest(rest(x)) | [2] |
x.rest.rest.first | first(rest(rest(x))) | 2 |
x.rest.rest.rest | rest(rest(rest(x))) | [ ] |
const y = x.rest.cons(4); | y = cons(4, rest(x)) | [4, 1, 2] |
关键观察点:,在最后一行中,x 和 y 共享了 [1, 2] 这个子链表的结构。内存中只有一个 [1, 2] 的副本,x 和 y 都指向它,但这是安全的共享,因为链表是不可变的
TypeScript 简写: 参数属性
class Cons<Element> implements ImList<Element> {
public readonly first: Element;
public readonly rest: ImList<Element>;
public constructor(first: Element, rest: ImList<Element>) {
this.first = first;
this.rest = rest;
}
public cons(first: Element): ImList<Element> {
return new Cons<Element>(first, this);
}
}TypeScript 提供了简写方式:在构造函数参数前加上 public / private / readonly,就能自动创建并初始化成员变量:
class Cons<Element> implements ImList<Element> {
public constructor(
public readonly first: Element,
public readonly rest: ImList<Element>
) {
}
public cons(first: Element): ImList<Element> {
return new Cons<Element>(first, this);
}
}这种写法同样适用于 private 字段,但要谨慎使用,因为直接把构造参数放进内部表示(rep)可能破坏封装性。
递归数据类型定义
抽象数据类型 ImList 以及它的两个具体类 Empty 和 Cons,共同构成了一个递归数据类型。 Cons 是 ImList 的一种实现,但它在自己的内部表示(rest 字段)中又使用了 ImList, 因此它在实现自身时递归地依赖于 ImList 的定义。
为了让这种关系更加直观,我们可以写出如下数据类型定义:
ImList<Element> = Empty + Cons(first: Element, rest: ImList<Element>)这是一种递归的定义形式,表示 ImList 是一组值的集合。高层意义如下:集合 ImList 中的值可以有两种表示方式: 要么是一个 Empty 对象(没有字段),要么是一个 Cons 对象,其字段包括一个元素 first 和一个列表 rest(该 rest 也是一个 ImList)。
更详细地说:ImList<Element> 是一个泛型类型,对于任意类型 Element, ImList<Element> 集合中的值要么由 Empty 表示,要么由 Cons 表示, 而 Cons 对象包含两个字段: first(类型为 Element)与 rest(类型为 ImList<Element>)。
当我们使用这种定义方式书写时,数据类型的递归特性就会非常清晰。例如,我们可以用这种表达形式来表示任意的 ImList 值: 列表 [0, 1, 2] 可以写作:
Cons(0, Cons(1, Cons(2, Empty)))我们还可以从基本情况(Empty)出发,通过递归地应用 Cons,构造出无限多种 ImList 值。例如,对于 ImList<boolean>:
| 构造层级 | 示例 |
|---|---|
| 基本情况 | Empty |
| 第一次递归 | Cons(true, Empty)、Cons(false, Empty) |
| 第二次递归 | Cons(true, Cons(true, Empty))、Cons(true, Cons(false, Empty))、Cons(false, Cons(true, Empty))、Cons(false, Cons(false, Empty)) |
| 第三次及以后 | Cons(true, ...)、Cons(false, ...) 等等 |
形式上,一个数据类型定义包括:
- 左边的抽象数据类型(即我们定义的类型名)
- 右边的表示(具体数据结构),由若干变体(variant)组成
- 各个变体用加号
+连接 - 每个变体的写法是
类名(字段名: 字段类型),字段可以为零个或多个
如果一个数据类型定义中,抽象类型在自己的定义中再次出现(例如字段的类型中),那么这个定义就是一个递归数据类型。
例如二叉树的定义:
Tree<Element> = Empty + Node(e: Element, left: Tree<Element>, right: Tree<Element>)
Tree 类型的值要么是 Empty,要么是 Node。 Node 包含一个元素 e(类型为 Element),以及左右两个子树。
这种定义方式称为代数数据类型(Algebraic Data Type, ADT)。在函数式编程中(如 Haskell、ML),代数数据类型的语法不同, 但核心思想相同:类型是多个变体的联合体(union),其中某些变体可能递归地引用自身。
在面向对象语言(如 TypeScript、Python、Java)中,我们通常用接口与类来实现这种结构。所以在写递归数据类型时,应该在实现类前加上类型定义说明,例如:
interface ImList<Element> {
// ...
}
// 数据类型定义:
// ImList<Element> = Empty + Cons(first: Element, rest: ImList<Element>)
class Empty<Element> implements ImList<Element> {
// ...
}
class Cons<Element> implements ImList<Element> {
// ...
}递归数据类型的函数
这种看待数据类型的方式——把数据类型理解为由具体变体构成的递归定义——不仅能优雅地处理列表、树等递归或无限结构,还能为描述在这些数据类型上定义的操作提供一种自然的方式:每个变体对应函数的一个分支。
首先,看看数据类型定义如何映射到抽象接口与具体实现: