Lec 7 性能
前面讲在单一机器上通过虚拟化内存、有界缓存、线程来增强模块化;了解了微内核和宏内核的区别;探讨了如何在单一物理机器上通过虚拟机加强模块化,使其能够运行多个OS实例(并且其中一个OS发生了BUG不会影响到其他OS崩溃),其中如何实现VMM是一个关键问题,解决方法是通过“trap-and-emulate",陷入并模拟。一个关键问题是,如何陷入那些不会引发中断的指令。
现在还有什么没有讨论呢? 性能。这节将会介绍提供性能的通用方法。
本节没有参考书资料
思考题
- 性能瓶颈是指什么?
- 在思考系统性能时,拥有系统模型有何帮助?
- 常见的性能指标有哪些?它们各自的含义是什么?它们之间的关系如何?
- 哪些系统级技术通常能提升性能?
- 硬盘读写操作是如何工作的:
- 对于机械硬盘(HDDs)?
- 对于固态硬盘(SSDs)?
- 为什么在机械硬盘上批量读取能提升性能?
- 假设我们要将一个大型数据库实现为一系列文件(即在文件系统之上实现数据库),我们需要考虑哪些事项?
- 数据库管理系统(DBMS)擅长做什么?
性能指标
性能的依据是测量,测量需要指标:
- 时延(Latency): 完成一个请求需要花费多长时间
- 吞吐量(Throughput):单位时间内能处理多少请求
- 利用率(Utilization): 资源被利用所占比重
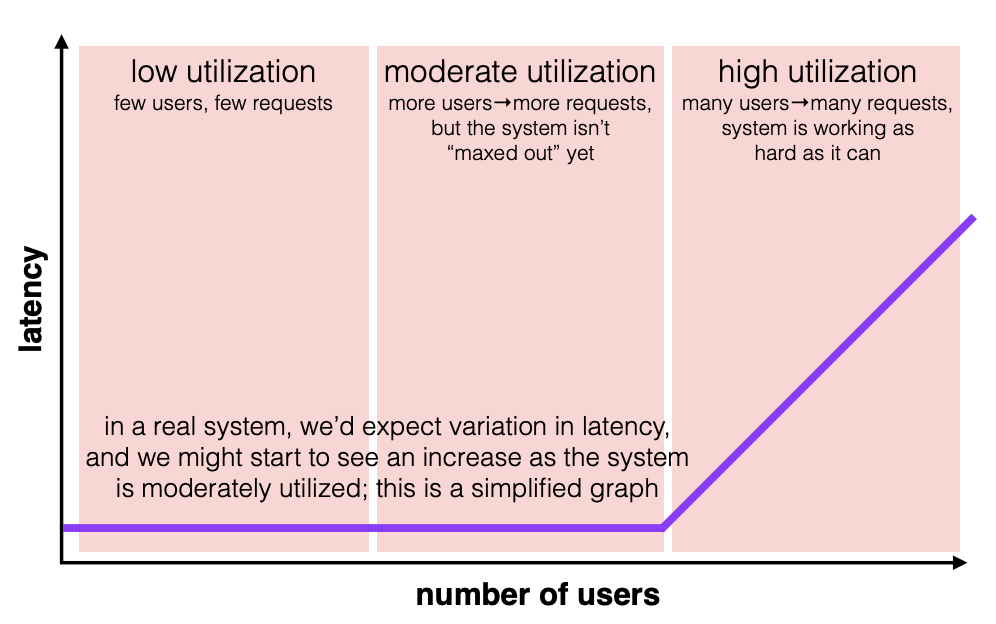
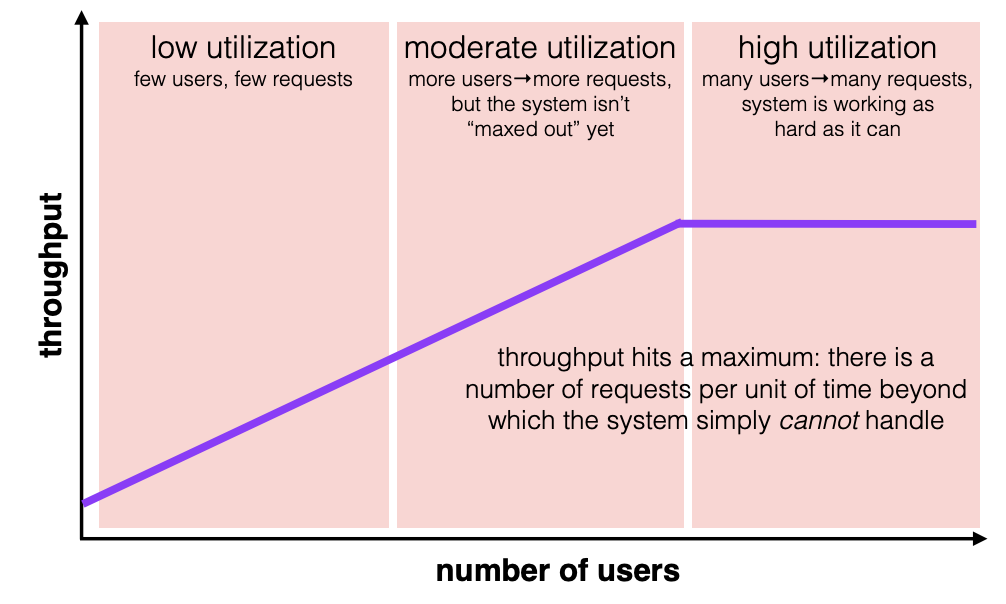
他们的关系取决于上下文,一般来说,随着系统负载增加:
- 一开始时延和吞吐量都很低,随着负载增加,吞吐量上升,而时延保持扁平
- 直到系统到达最大吞吐量后,吞吐量停滞,时延增加。
对于需要高负载的系统,我们会更加关注吞吐量。
以下几种技术是常用的瓶颈缓解手段:
- 批处理
- 缓存
- 并发
- 调度
硬盘工作原理
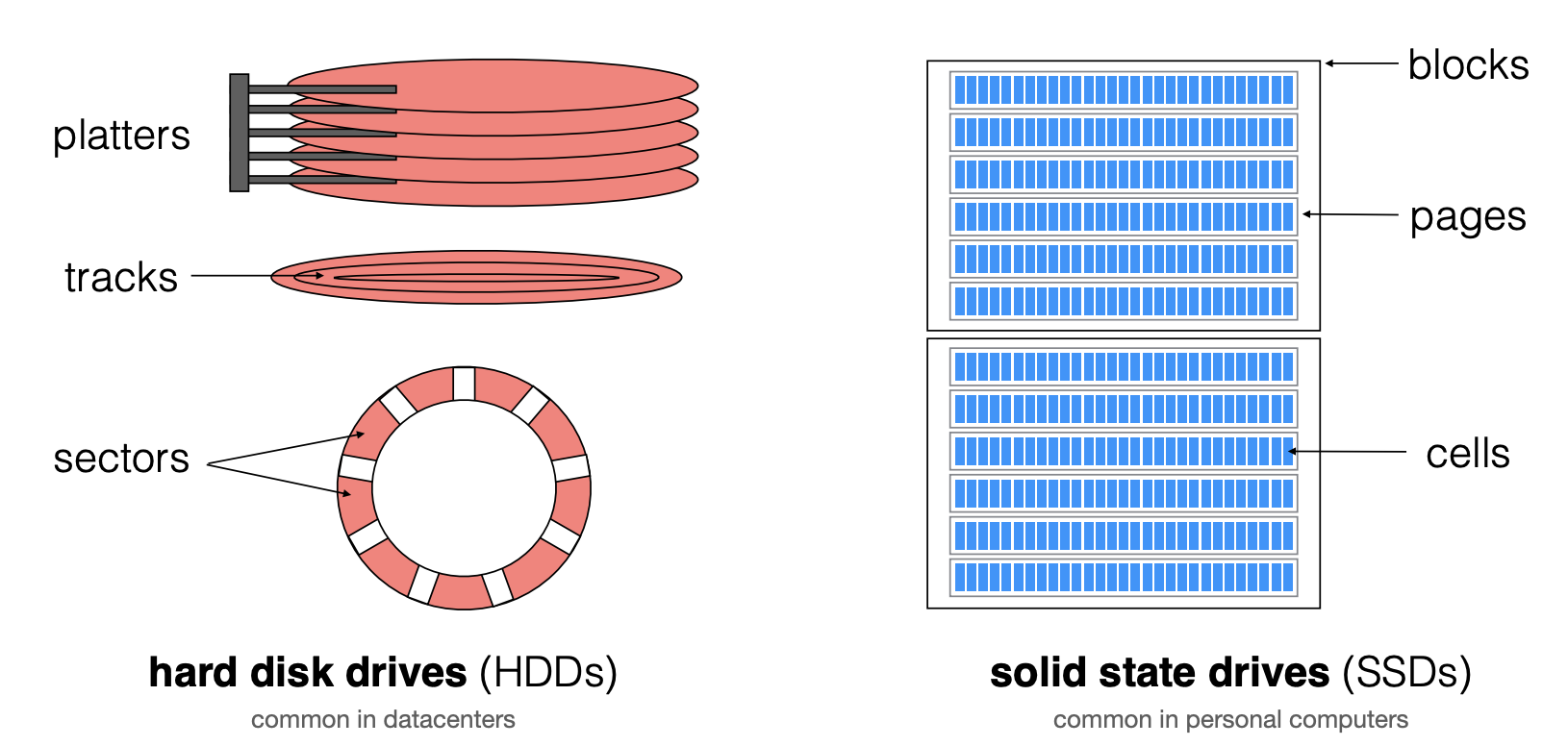
下面是HDD和SDD的组成图。我们先学习磁盘的工作原理:
- 磁盘由多个磁盘盘片(platters)组成,这些盘片安装在一个旋转轴(axle)上并高速旋转
- 每个盘片的两面都包含同心圆磁道(tracks),每个磁道有被划分为多个扇区(sectors)
- 柱面(cylinder):位于不同的盘片上,垂直对齐的一组磁道
- 磁盘臂(disk arm)上有多个磁头(head),每个盘面对应一个磁头,所有磁头会同步移动
- 每个磁头在盘片旋转经过时,对扇区进行R/W操作
- 扇区大小是磁盘的基本读写单位,通常为512B
- 为了实现读写,该过程如下
- 磁头寻道(seek):移动磁盘臂,将磁头定位到目标磁道
- 等待旋转(rotational latency):等待盘片旋转到目标扇区进入磁头下方
- 数据传输:执行读写操作
一个磁盘的规格信息:

磁盘R/W需要花多长时间?
Solution:寻道时间: 读8.2ms, 写9.2ms;旋转时间: 0-8.3ms; 数据传输速率为 35~62MB/秒,因此随机读写一个4KB块所需时间:8.2ms + 4.1ms + ~.1ms = 12.4ms 吞吐量为 4KB/12.4ms = 322KB/s;99%的时间花在磁盘的机械移动上,而不是实际的数据传输。
性能优化方法
下面介绍几个磁盘性能优化方法。
批处理
- 使用Flash
- 批处理多个传输。
- 如果是顺序访问数据,效率会更高:
- 寻道到相邻磁道: 0.8ms
- 读取整个磁道: 8.3ms
- 总时间: .8 + 8.3 = 9.1ms
- 单磁道数据量:
- 1000 sector * 512 B/sector = 512KB
- 吞吐量计算: 512KB/9.1ms = 55MB/s
- 如果是顺序访问数据,效率会更高:
结论:尽可能避免随机访问,尽可能进行长时间的顺序读取。如果读写大文件,尽量将文件存储在磁盘上的连续区域;如果经常读取小数据块,应尽可能对数据进行分组,减少磁头移动次数,提高访问效率。
缓存
我们在 DNS 中已经见过缓存的应用。缓存是提升系统性能的常见方法。
如何衡量缓存的效果?
平均访问时间 =
命中时间 * 命中率 + 未命中时间 * 未命中率目标:提高命中率(hit rate)
关键问题:如何选择要从缓存中淘汰(evict)哪些数据?
- 最近最少使用(LRU, Least Recently Used)
缓存的适用场景:
- 所有数据都能放进缓存(缓存足够大)
- 数据访问具有局部性(Locality)
核心经验:构建高效缓存需要理解数据访问模式;就像优化磁盘性能一样,减少缓存成为瓶颈的关键在于理解底层工作原理
并发/调度
示例:
- 5 个并发线程发出读请求,目标磁盘扇区分别是 71、10、92、45、29。
- 朴素算法:按请求顺序读取,每次都重新寻道,效率低。
- 优化算法:按照磁道号排序,按顺序处理请求,提高吞吐量。
- 问题:这种调度可能不公平(例如,总是优先处理某些请求)。
结论:调度没有唯一正确答案,需要在性能与公平性之间权衡。
并行化
目标:有多个磁盘,希望并行访问它们,提高性能。
关键问题:如何在多个磁盘之间分布数据?
情况 1:大量小文件请求,受磁盘寻道时间限制
✅ 解决方案:把每个文件放到单独的磁盘上,让多个磁盘可以并行寻道和访问不同文件。
情况 2:少量大文件请求,受顺序吞吐量限制
✅ 解决方案:使用条带化(Striping),把一个大文件拆分成多个部分,分布在多个磁盘上,提高顺序读写速度。
情况 3:跨多台计算机的并行存储
- 问题:如何处理机器故障?
替代技术
SSD,通常是基于闪存(Flash Memory),但仍然提供了传统的磁盘接口。闪存的特点是:无机械部件。性能对比:
示例规格:
- 顺序读取:400 MB/s
- 顺序写入:200-300 MB/s
- 随机 4K 读取:5700 次/秒(23 MB/s)
- 随机 4K 写入:2200 次/秒(9 MB/s)
结论:
- 顺序访问仍然远比随机访问块,
- 写入性能明显更差(尤其是小块写入)
- 闪存只能按大块擦除,小块写入时需要读取整个块-> 修改 -> 写回
- 现代SSD通过复杂的控制器优化这个问题
- 仍然可以通过批量操作(batching)减少小块写入
总结
- 不能盲目地应用优化技术,必须理解底层系统的工作原理。
- 批处理: 需要理解磁盘访问的工作方式。
- 缓存: 需要理解数据访问模式
- 调度、并发: 需要理解磁盘如何访问,系统的实际工作负载
- 并行: 要理解具体的工作负载类型
核心要点:优化系统性能的关键,在于深入理解系统的底层机制!
论文: Unix 分时系统(II)
从第5章开始,阅读完后你应该知道在UNIX的进程的基本情况(比如,fork()如何工作,内存如何共享,进程如何通信);读完第6章,你应该知道shell的基本你请客,当你输入UNIXshell命令时,发生了什么?有多少进程参与了
文件系统
实现
一个目录项只包含一个关联文件的名称和一个指向文件本身的指针。这个指针是一个整数,称为文件的 i-number(index number)。当访问某个文件时,它的 i-number 将被用作索引,对一个由该目录所在设备的已知区域内所保存的系统表(即 i-list)进行查找。由此找到的条目(文件的 i-node)包含的文件描述如下:
- 所有者
- 保护位
- 物理磁盘或磁带存放文件内容的地址
- 文件大小
- 最后修改时间
- 文件的链接数,即该文件在目录中出现的次数
- 一个二进制位,表明该文件是否为目录
- 一个二进制位,表明该文件是否为特殊文件
- 一个二进制位,表明该文件是 “大文件” 还是 “小文件”
open 或 create 系统调用的目的是通过搜索显式或隐式命名的目录,将用户给出的路径名转换成 i-number。一旦文件被打开,它的设备、i-number 和读写指针就会被存储在一张系统表中,该表由 open 或 create 返回的文件描述符进行索引。因此,后续对文件调用读或写时提供的文件描述符,可以很容易地关联到访问文件所需的信息。
创建一个新的文件时,会给它分配一个 i-node,并建立一个包含文件名和 i-node编号(译注:即 i-number)的目录项。要链接到一个现有的文件,需要创建一个带有新名称的目录项,从原来的文件条目中复制 i-number,并递增 i-node 的链接数(link-count)字段。移除(删除)一个文件,则是通过递减其目录项所指向的 i-node 的链接数,并删除该目录项。如果链接数减到 0,文件占用的任何磁盘块都会被释放,i-node 也会被解除分配。
文件系统被划分为若干512字节的块,每个i-node上有一块区域可存放8个"设备地址",一个(非特殊)小文装进不大于8个块的大小,此时i-node上存的是块本身的地址。对于大文件,需要间接寻址,一个间接块可以存放256个块地址,所以最大能存8 * 256 * 512 = 2^20 个字节。
对于特殊文件,后7个"设备地址"没啥用,该列表被解释为一对构成内部设备(device)名称的字节。这些字节分别指定了设备类型和子设备号。设备类型表示该设备上的 I/O 将由哪种系统程序处理;子设备号则用于选择,例如,选择连接到某一控制器上的磁盘驱动器、选择数个打字机接口中的一个。
在这种环境下,mount 系统调用 (§3.4) 的实现非常简单。mount 维护了一个系统表(译注:一个映射关系),它的自变量是 mount 过程中指定的普通文件的 i-number 和设备名,对应的值是指定的特殊文件的设备名。在 open 或 create 过程中扫描路径名时,会对每一组 (i-number,device) 进行搜索,如果发现匹配,i-number 就会被替换成 1(也就是所有文件系统中根目录的 i-number),设备名则替换成表中对应的值。
在用户看来,文件的读和写都是同步的,没有缓冲。也就是说,在 read 调用返回后,数据立即可以使用,反之,在 write 之后,用户的工作空间可以重新使用。实际上系统维护了一个相当复杂的缓冲机制,大大减少了访问文件所需的 I/O 操作次数。下面假设进行了一次 write 调用,指定传输一个字节