Lec 16 事务(原子性+隔离性)
阅读参考书 §9.1,§9.2.1,§9.2.2
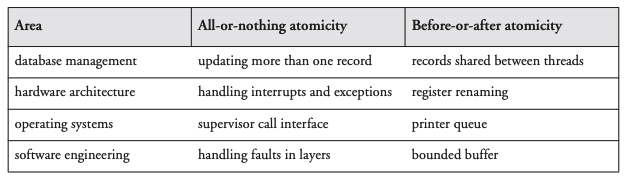
系统工程设计有两个策略,一个是all-or-nothing原子性、另外一个是before-or-after 原子性,他们都提供了很强的模块化性质,隐藏了一个事实——原子步骤实际上包含了很多步骤。
Outline
- 原子性
- 隔离性
16.1 原子性
原子性是很多计算机系统领域需要的性质,包括数据库、硬件架构、OS的接口等等。
我们的目标是用不可靠的组件构建可靠的系统。我们希望构建能够服务众多客户端、存储大量数据、性能良好的系统,同时保持高可用性。处理故障的高层次过程是识别故障、检测/遏制故障并处理故障。在课堂上,我们将构建一套抽象方法,使这个过程更易于管理。
原子性
def tranfer(bank_file, account_a, account_b, amount):
bank = read_account(bank_file)
bank[account_a] = bank[account_a] - amount
bank[account_b] = bank[account_b] + amount
write_account(bank_file) ---- crash!这样做有个问题: 在write_accounts()执行途中crash了,bank_file会处在一个中间状态。
def tranfer(bank_file, account_a, account_b, amount):
bank = read_account(bank_file)
bank[account_a] = bank[account_a] - amount
bank[account_b] = bank[account_b] + amount
write_account(tmp_file)
rename(tmp_file, bank_file) ---crash!实际上rename()途中发生crash潜在地也会让bank_file处在中间状态,知识转移了问题。一个办法是,把rename做成原子的。
让rename()变成原子的,要比write_accounts()变成原子的更加可行。为什么?简单回答就是rename操作要比较简小。
这里简单用Unix文件系统为例,介绍相关的数据结构。
目录条目是文件系统中的一个结构,用于将文件名映射到相应的 inode,文件名为 "bank_file" 的文件与 inode 1 相关联。

在这个例子中,我们有三件事情正在发生。
- 我们需要将银行文件的条目指向新的数据,即指向inode 2
- 删除有关临时文件的目录条目,因为他的内容已经被转移到了orig_file,删除目录条目意味着再通过tmp_file名字来访问inode2
- 减少inode1的引用计数。
def rename(tmp_file, orig_file):
tmp_inode = lookup(tmp_file)
orig_inode = lookup(orig_file)
# point orig_file's dirent at inode 2
orig_file dirent = tmp_inode
# delete tmp_file's dirent
remove tmp_file dirent
# remove refcount on inode 1
decref(orig_inode)我们假设如果执行到orig_file dirent = tmp_inode时发生crash,则情况看起来很糟糕,实则无伤大雅,因为单个扇区的写操作是原子的。
但是如果执行到 remove tmp_file dirent crash了,那么引用计数将会是错误的
解决方案: 从失败中恢复(清理干净)。
def recover(disk):
for inode in disk.inodes:
inode.refcount = find_all_refs(disk.root_dir, inode)
if exists(tmp_file):
unlink(tmp_file)这个方法有个名称, “影子副本”(shadow copy),将更新数据写入到临时文件,然后原子性地切换到新副本,最后移除旧副本。。有一个可靠的恢复过程意味着系统可以容忍一定程度的中间状态不一致或错误,因为这些问题可以在故障发生后通过恢复过程来修复。这种设计理念简化了系统实现。
为什么这种方法可行?
因为我们进行的是单扇区的写入。它需要从较底层获取一些原子性。这实际是原子操作的通用方法。
正确性和可序列化
应用无关是模块设计的一个目标:我们希望在不涉及应用逻辑正确性的前提下,单独论证before-or-after原子性的机制是正确的。确实存在这样的一种正确性概念,:如果所有并发操作的执行结构都保证是某种纯串行执行的可能结果,那么我们就认为这些操作的协调是正确的。
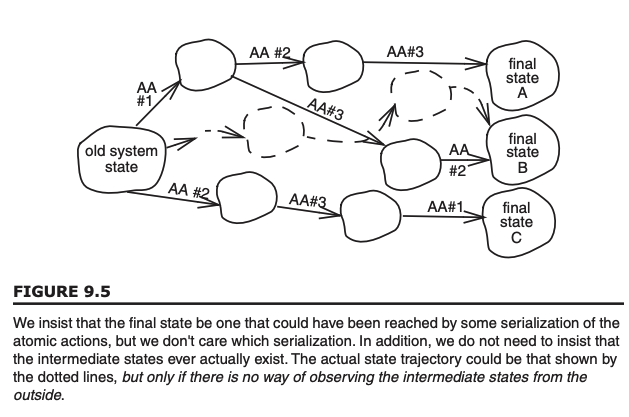
我们不需要严格按照图9.5某条特定路径遍历中间状态。相反,系统可以沿着虚线轨迹,经过某些中间状态,甚至这些状态本身并不符合应用定义下的正确性要求。
在某些应用中,正确性要求甚至比可串行化更严格。例如
- 银行系统的设计者希望避免时间上的错乱,因此要求外部时间一致性(external time consistency);如果有外部证据(例如打印的收据)表明前后原子动作 T1 结束后,前后原子动作 T2 才开始,那么在系统内部的串行化顺序也应该是 T1 在 T2 之前。
- 处理器架构设计中,可能需要顺序一致性(sequential consistency):即当处理器并发执行多个指令时,其执行结构应当等同于按照程序员指定顺序依次执行这些指令的结构。
回到我们的例子,一个真实的转账应用有多个不同的before-and-after原子性需求。考虑下面的审计过程, 他的目的是验证所有账户的余额是否为零。(复式记账中,属于银行的账户,例如保险库中的现金金额,通常为负余额)
def AUDIT():
sum <- 0
for each W <- in bank.accounts
sum <- sum + W.balance
if (sum != 0) call for investigation假设AUDIT在一个线程中运行,同时另外一个在执行转账,如果AUDIT在转账前检查账户A,但在转账后检查账户B,那么他将计算两次,从而得出错误的结果。
原子性的两种形式:all-or-nothing(全有或全无原子性)和before-or-after(前后原子性)有统一目标:隐藏一个动作的内部结构。With that insight, 它是一个统一的概念,原子性——如果一个操作的内部实现结构无法被更高层次发现,那么该操作就是原子的。这是两种视角下,第一种角度是从调用操作(action)的线程内部的其他模块出发,第二种角度则是从其他线程出发。
我们前面看原子性都是外部视角,对于实现者的视角,他清楚这个操作实际上是由多个步骤组成的复合操作, 并且需要做一些额外的工作来向高层次隐藏细节。 调用层之间的接口层就是定义原子操作的关键部分。
隐藏原子的操作的另外一个方面是,允许原子操作有一些“副作用”,一个常见的例子是审计日志,当原子操作遇到问题时,它会记录检测到的故障性质和恢复过程,以便后续分析。审计日志通常是实现原子操作的层的私有记录;在正常操作过程中,它对该层以上的部分是不可见的,因此,当发生故障回滚时,审计日志不需要回滚。另一个有益副作用的例子是性能优化, 当上层原子操作要求DBMS向文件中插入一条新记录时,DBMS可能会出于性能优化的考虑,决定此时重新排列文件以使其物理顺序更优。如果原子操作失败并中止,它只需要确保新插入的记录被移除;文件不需要恢复到之前效率较低的存储排列方式。
All-or-Nothing 的实现
我们使用自举方法来解决从任意代码序列创建前后原子性(Before-or-After Actions)的问题,第一个例子就是ALL_OR_NOTHING_PUT,它对单个磁盘扇区执行全有或全无(all-or-nothing)的PUT 操作,使得稍后 GET 读取该扇区时,总是返回旧数据或新数据之一,而不会得到混杂的内容。
NOTE
自举技术(bootstrapping):类似数学归纳法,基本思路是:
- 首先,寻找一种系统化方法,将一个一般性问题 归约 为一个特殊情况的狭窄版本
- 然后,针对该特殊情况,使用某种特定的方法来求解。这种方法可能只适用于该特殊情况,因为它可以利用特定场景的特点。
- 最后,完整的通用解决方案 由 两部分 组成:
- 该特殊情况的解决方法
- 一种系统化方法,能够将一般问题规约到该特殊情况。
可容忍错误的规范意味着,在可能的范围内,整个系统应尽可能地做到快速失败(fail-fast):如果在更新过程中出现问题,系统会在处理任何新的请求之前立即停止运行,从而让用户意识到系统已经停机。为了进一步简化,我们暂时假设磁盘不会衰退,也不存在硬错误。(由于这种完美磁盘假设显然不现实,但是通过一些技术仍然能够实现全有或全无原子性)。在完美磁盘假设下,唯一可能出错的情况是:系统在关键时刻崩溃。系统崩溃后,磁盘上最多可能有一个扇区损坏, 但使用该接口的客户端可以放心以下两点:
- 可能损坏的扇区只有一个。
- 如果该扇区确实损坏了,任何后续读取该扇区的操作都能检测到问题。
在处理器模型和存储系统模型的共同作用下,所有预期的故障最终都会导致同样的结果。我们可以利用虚拟化来设计一个简单但稍显低效的方案: 为每个需要全有或全无属性的数据扇区分配三个物理磁盘扇区,分别标记为 S1、S2 和 S3。 这三个物理扇区一起构成了一个虚拟“全有或全无扇区”。在系统中,凡是原本使用单个磁盘扇区的地方,现在都改用该三重扇区 {S1, S2, S3}。我们首先设计一个几乎正确的全有或全无实现,命名为 ALMOST_ALL_OR_NOTHING_PUT,然后找到其中的 bug,并修复它,最终得到一个正确的 ALL_OR_NOTHING_PUT。
ALMOST_ALL_OR_NOTHING_PUT
在写入数据时,该方法按照以下顺序写入数据:
- 先写入 S1,等待完成。
- 再写入 S2,等待完成。
- 最后写入 S3,等待完成。
由于系统在每次写入后都会等待完成,因此如果系统崩溃,最多只会影响其中一个扇区。
ALL_OR_NOTHING_GET
在读取数据时,该方法按照以下规则处理:
- 如果 S1 和 S2 的内容相同,则返回该值,作为全有或全无扇区的值。
- 如果 S1 和 S2 的内容不同,则返回 S3 的内容,作为全有或全无扇区的值。
图9.6展示了几乎正确的伪代码实现。

如果发生系统崩溃,他的实现行为又该如何。假设在前面有一个记录已经正确写入到all-or-nothing扇区(换句话说,三个副本都相同),这时有人调用ALL_OR_NOTHING_PUT更新了,目标就是即便发生崩溃,通过调用ALL_OR_NOTHING_GET也能得到一个一致且完整的版本记录。假设系统在顺利完成S2的写入之前就崩溃了,这样导致S1或者S2损坏,这种情况下,ALL_OR_NOTHING_GET 读取 S1 和 S2 时会发现它们的值不同,无法确定哪个是正确的。但由于系统是fail-fast(快速失败)的,S3还未被ALMOST_ALL_OR_NOTHING_PUT修改,仍然包含旧值。假设 ALMOST_ALL_OR_NOTHING_PUT 在成功写入 S2 之后才崩溃,这种情况下,崩溃可能损坏S3,但S1和S2都包含新值。因此ALL_OR_NOTHING_GET可以安全返回S1的值。
这种设计有什么问题吗? ALMOST_ALL_OR_NOTHING_PUT假设它在开始执行时,S1、S2和S3的数据完全一致的。但之前崩溃可能会破坏这一假设,导致后续的PUT和GET出错。假设ALMOST_ALL_OR_NOTHING_PUT在写入S3时候崩溃,下一次调用ALL_OR_NOTHING_GET时发现S1 = S2,按预期返回S1的值。一个新线程这时候调用ALMOST_ALL_OR_NOTHING_PUT,但在写入S2时崩溃,现在S1 ≠ S2,返回了已损坏的S3。

如何修复这个问题。在ALL_OR_NOTHING_PUT必须确保在更新前,S1、S2和S3三个扇区的数据完全相同。为此引入一个CHECK_AND_REPAIR 过程(如图9.7),大致逻辑,比较S1、S2和S3的数据,如果不相同,则强制变相同,仅需要处理7种可能的数据状态。
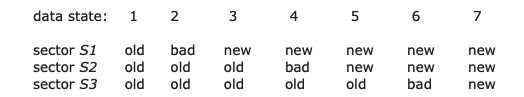
阅读该表的方法如下:如果三个扇区 S1、S2 和 S3 都包含“旧”值,则数据处于 状态 1,如果三个副本相同,要么是状态 1 要么是状态 7,因此CHECK_AND_REPAIR直接返回,如果不满足,但S1和S2相同,那么数据一定在状态5或6,此时令S3的值与S1、S2一致,直接返回。如果S2和S3相同,则数据一定在状态2或3、此时令S1与S2、S3一致,剩下的可能性是状态4,此时S2是损坏的,S1包含新值,S3仍然是旧值,此时如何选择是任意的,在该算法中选择将S1复制到S2和S3,保持三者一致。
如果CHECK_AND_REPAIR在运行过程中崩溃了怎么办? 要么从状态4往前推进到状态7,要么从状态3向后回退到状态1。如果 CHECK_AND_REPAIR 自身在执行过程中被系统崩溃中断,那么重新运行它时,会从上次失败的位置继续执行,最终仍能修复数据。
总结起来,有几点观察:
- 算法的任意时刻,只有一个线程在执行
ALL_OR_NOTHING_GET或者是ALL_OR_NOTHING_PUT CHECK_AND_REPAIR具有幂等性。线程可以启动 CHECK_AND_REPAIR 过程,在执行该过程的任何一步时被系统崩溃中断,之后再从头开始执行 CHECK_AND_REPAIR 任意次数,ALMOST_ALL_OR_NOTHING_PUT的(CAREFUL_PUT操作)是提交点(commit point)- 虽然该算法写入了 3 份数据副本,但其主要目的是确保原子性,而非提供持久性(durability)
相关工作
在实现全有或全无磁盘扇区的方法有很多种,还有一些磁盘衰退(decay event)的容错模型,该模型无法屏蔽系统崩溃,但是通过RAID技术来屏蔽磁盘衰退,从而实现持久性。在本节中,我们采用了一种不同的容错模型,它不考虑磁盘衰退,而是专门设计用来屏蔽系统崩溃。真正理想的方案应该是从一个同时考虑系统崩溃和磁盘衰退的容错模型出发,设计出既具备全有全无原子性(all-or-nothing),又具备持久性(durability)的存储方案。
系统化的原子性: 提交与黄金法则
ALL_OR_NOTHING_PUT 和 ALL_OR_NOTHING_GET 这两个示例展示了一种特殊情况下的全有全无原子性(all-or-nothing atomicity),但它们并没有提供系统化的方法来构造更通用的全有全无操作。
理想情况下,我们希望能够将程序中的任意一系列指令包裹在某种开始(begin)和 结束(end)语句之间,然后期望编译器和操作系统执行某种“魔法”,让这段代码自动变成全有全无的操作。然而,目前没有人知道如何实现这一点。不过,如果程序员愿意做出一定让步,我们可以接近这个目标。这种让步体现在对全有全无操作的各个步骤施加一定的规则,即遵循一种纪律性(discipline)。该规则的核心是确定某个步骤作为提交点(commit point)。基于此,全有全无的操作可以分为两个阶段:
- 提交前。这个阶段程序确保无论发生什么情况,都必须能够回滚该操作,并且不会留下任何痕迹。
- 确定完成操作所需的资源、并确保可用,以满足后面”一路执行到底,不可失败“的要求
- 具备中止(abort)的能力,意味着任何更改都是可撤销的。一旦某个共享资源被预留,就不能释放,直到提交点被越过。
- 提交后。这个阶段程序必须确保,无论发生什么情况,该操作都必须成功执行到底。
- 暴露计算结构
- 释放已预留但是不需要的资源
- 执行外部可见操作
如果系统崩溃发生在提交后阶段呢?
乍一看,如果系统在提交后阶段崩溃,似乎一切都无法挽回。因此,为了确保全有全无原子性,最简单的方法是把提交步骤放在全有全无操作的最后一步。实际上,这一要求并不这么严格。一个关键的特点是: 提交后阶段是封装在实现全有或全无操作的层次内部
原子性的黄金法则
IMPORTANT
永远不要修改唯一的副本!
为了确保一个复合操作是全有全无的,必须有办法撤销提交前阶段的所有更改。深入研究全有全无原子性的各种实现方案,我们会发现,正确的实现最终都会归结为影子拷贝,原因是它确保遵循了黄金法则。
16.2 隔离性
隔离性指的是一个操作(A1)的效果如何以及何时对另一个操作(A2)可见。在课程中,我们的目标是实现高度的隔离性,使得 A1 和 A2 看起来像是按顺序执行的,即使它们实际上是并行执行的
事务通过提供原子性和隔离性来保护数据一致性,使得系统在处理并发操作和故障时更加可靠和易于管理。事务的这些特性简化了并发控制,减少了手动管理并发和故障恢复的复杂性

原子性:通过影子拷贝实现了单个用户和文件的原子性,但这种方法的性能很差,无法扩展到大规模系统。
隔离性:目前还没有实现有效的隔离性。粗粒度锁虽然简单但性能差,而细粒度锁虽然性能好但实现复杂且难以推理。