Lec 13 长尾延迟
阅读资料
IX: a protected dataplane operating system for high throughput and low latency, OSDI'14
- Awarded Best Paper
商业操作系统在应用程序每秒钟需要数百万次操作时才能保持高吞吐量和低(尾)延迟,对于最慢的请求只需几百微秒。通常认为对于高性能网络(小信息的高包率、低延迟)的构建,最好都是在内核之外构建用户态协议,IX提出了dataplane operating system,提供高IO性能同时保持内核的安全性。IX通过硬件虚拟化技术分离内核网络处理的调度和管理
论文阅读: The Tail at Scale
快速响应用户操作(在100毫秒内)的系统比响应时间较长的系统更能让用户感到流畅和自然。
互联网连接的改善以及仓库级计算系统的兴起使得Web服务能够在查询多个TB的数据集时提供流畅的响应能力,跨越数千台服务器。例如,Google搜索系统会在用户输入时实时更新查询结果,根据用户已输入的前缀预测最可能的查询,执行搜索并在几十毫秒内显示结果。
在一堆不可靠的组件上组建一个可靠的整体,我们称为tolerant,容错性。同样的,在一堆不可预测的组件上创建一个响应可预测的整体,我们称之为"延迟尾容忍(latency tail-tolerant)"。
1. 尾时延的影响
尾延迟问题对分布式系统的影响主要体现在以下几个方面:
- 首先,用户体验下降。对于交互式服务来说,延迟的增加会直接导致用户满意度的降低。
- 其次,资源利用率降低。由于尾延迟问题,系统可能无法充分利用资源,导致资源浪费。
- 最后,系统稳定性下降。尾延迟问题可能导致系统性能的不稳定,增加系统崩溃的风险。
举个例子即使每个服务器通常在10ms内响应,但由于P99延迟(即99%的请求在多少时间内完成)可能高达一秒,当请求在大量服务器上并行处理时,大部分用户的请求将需要超过一秒才能完成。

关键洞察
- 在大规模分布式系统中,偶发的系统性能卡壳(hiccup)也会影响大规模分布式系统中大量的请求
- 在大规模系统中消除所有延迟变异源是不现实的,特别是在共享环境中。
- 采用类似于容错计算的方法,尾容忍软件技术将不可预测的部分组成一个可预测的整体
2. 抖动(Variability)存在的成因
- 资源共享(Shared resource): 除了机器本身的共享资源(CPU,缓存,网络,内存带宽等等),还包括同个应用的不同请求
- 守护进程(Daemons): 被调度起来的后台守护进程可能会产生数毫秒的卡壳(hiccups)
- 全局的资源共享:多个不同机器上的app竞争全局资源(网络交换机,共享文件系统等)
- 维护活动(maintenance activities):后台活动(如分布式文件系统中的数据重建、存储系统(如BigTable)中的定期日志压缩以及垃圾回收语言中的定期垃圾回收)可能会导致延迟的周期性峰值
- 排队:中间服务器和网络交换机中的多层排队会放大这种变异性。
- 电力控制/能源管理
- 功率限制:现代CPU设计会临时超过平均功率,这种情况可能会通过节流来降低产生的热量。
- 垃圾回收:固态存储设备提供非常快速的随机读访问,但需要定期回收大量数据块的垃圾回收操作,可能使读取延迟增加100倍
- 能源管理:许多设备的节能模式可以节省大量能量,但在从非活动模式切换到活动模式时会增加额外的延迟。
3. 组件级抖动通过规模放大
在大规模在线服务中,减少延迟的常见技术之一是将子操作并行化到许多不同的机器上,每个子操作与其对应的大数据集部分共同部署。并行化通过将请求从根服务器分发到大量叶服务器,并通过请求分发树合并响应来实现。这些子操作必须在严格的时间限制内完成,才能让服务感觉到响应迅速。
个别组件的延迟分布中的抖动在服务级别被放大。例如,假设一个系统中每个服务器通常在10毫秒内响应,但其99百分位的延迟为一秒。如果一个用户请求只由这样一台服务器处理,那么每100个请求中会有1个请求较慢(延迟1秒)。下面的图表说明了在这种假设场景中,服务级延迟是如何受到极少数延迟异常值影响的。如果一个用户请求必须从100台这样的服务器并行收集响应,那么63%的用户请求将超过1秒(图中标记为“x”)。即使对于每1万个请求中只有1个请求在单个服务器级别超过1秒延迟的服务,若该服务有2000台这样的服务器,几乎五分之一的用户请求也会超过1秒延迟(图中标记为“o”)。
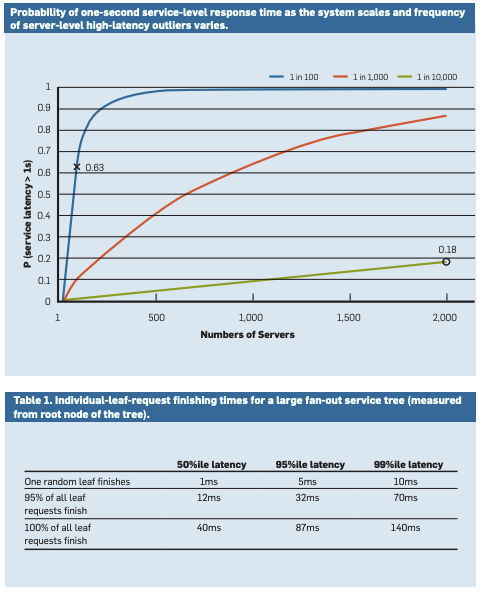
表1列出了来自一个实际Google服务的测量数据,该服务在逻辑上类似于这个理想化的场景;根服务器将请求通过中间服务器分发到大量叶服务器。表格显示了大规模分发对延迟分布的影响。一个单独的随机请求完成的99百分位延迟,在根服务器上测量为10毫秒。然而,所有请求完成的99百分位延迟为140毫秒,95%的请求完成的99百分位延迟为70毫秒,意味着等待最慢的5%的请求完成是导致总99百分位延迟的一半。集中处理这些慢响应的异常值的技术可以大幅度降低整体服务性能
3.1 降低组件级抖动方法
- 消除组件层面的波动:通过限制资源、软件实时性设计和提高稳定性来减少延迟波动。例如,可以采用实时操作系统(RTOS)来确保软件的实时性,通过优化算法和数据结构来减少资源争用。
- 根据服务类别差异化差异化及更高层次的队列机制:可以让非交互的请求之前有限调度用户正在等待的请求。保持底层队列的短小可以让上层策略更快产生效果
- 消除线端阻塞:将耗时较长的请求分割为多个可以交替执行的请求,从而降低线端阻塞对系统性能的影响。
- 管理后台活动和同步触发:优化后台活动,如垃圾回收、日志压缩等,以减少它们对系统性能的影响。例如,可以采用节流、将高负荷操作分割为低负荷操作以及在低负载的时候触发后台活动等方法。
- 捆绑请求:在多个服务器上排队请求,并使服务器之间能够知道彼此的等待状态。当一个服务器开始处理请求时,需要告知其他服务器取消等待,从而减少资源浪费和延迟。
综上所述,《The Tail at Scale》为我们揭示了大规模分布式系统中尾延迟问题的成因、影响及可能的解决策略。开发人员可以根据这些策略来优化分布式系统性能,提高用户体验和资源利用率,增强系统稳定性。在实际应用中,我们可以结合具体场景和需求选择合适的策略来应对尾延迟挑战。