6.5830 数据库系统
6.5830/6.5831: Syllabus 2024 (mit.edu)
先修课程
6.1210/6.006 Introduction to Algorithms
6.1800 Computer System Engineer
课程描述
这门课程旨在介绍数据库系统的基础知识,重点包括关系代数(relational algebra)和数据模型(data model)、查询优化(query optimization)、查询处理(query processing)、事务处理。这不是一个关于数据库设计和SQL编程的课程。但欢迎没有数据库经验的同学参加。
具体形式
课堂由基于数据库文献的讲座 + 7个作业(4个实验 + 3个作业集 + 2次考试组成)
课程目录
SQL
1 关系模型、SQL(Part I)
2 SQL(Part II)
3 Schema设计
索引和查询
4 数据库的内部架构
5 数据库存储管理(操作和查询处理)
6 内存管理
7 索引和访问方法
8 Join算法
9 查询执行器
10 查询优化
11 分析型数据库架构
并发控制和恢复
12 事务与加锁
13 乐观并发控制与多版本并发控制
14 故障恢复
15 高级基数估计
分布式数据库
15 并行数据库
16 分布式事务
17 最终一致性
18 高性能事务
19 集群计算(Spark)
20 SnowFlake
参考书
Readings in Database Systems, 5th Edition (redbook.io),俗称数据库小红书
实验
GoDB介绍
- 一个基本的数据库系统
- SQL从前端到后端
- 堆文件(Lab1)
- 缓冲池(Lab1)
- 基本操作(Lab1 & 2)
- 扫描、过滤、联接、聚合
- 事务(Lab3)
- 恢复(Lab3)
- 查询优化
- B树索引
例子
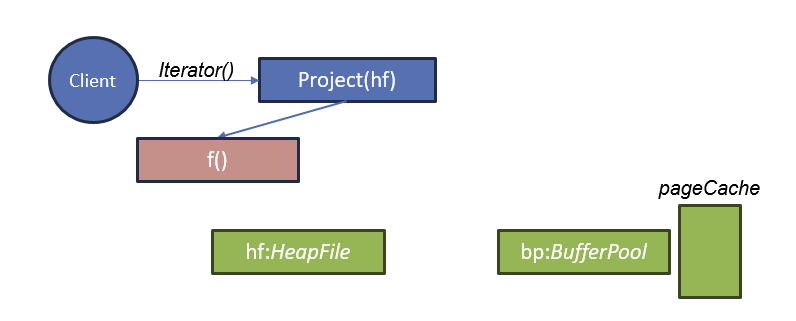
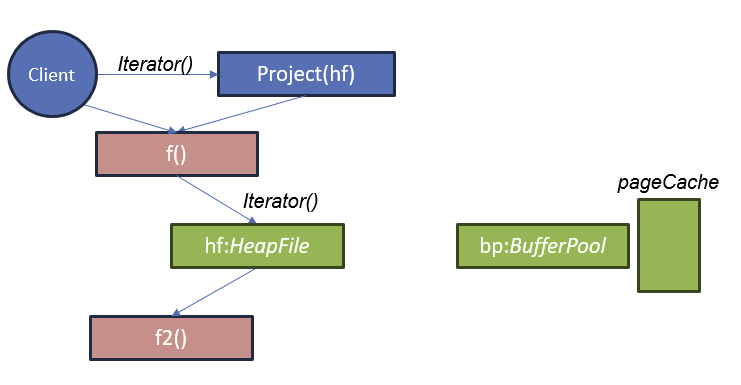
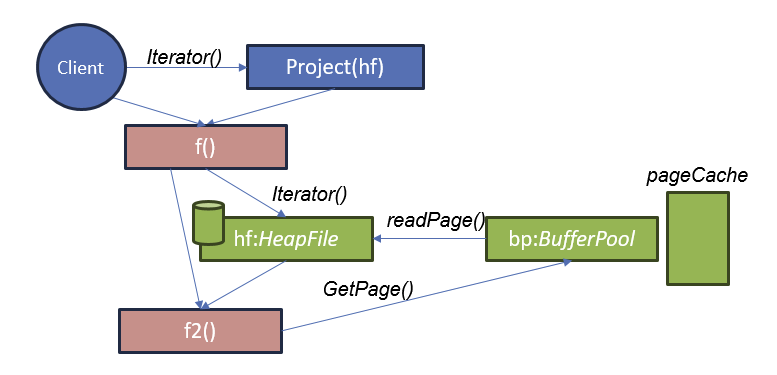
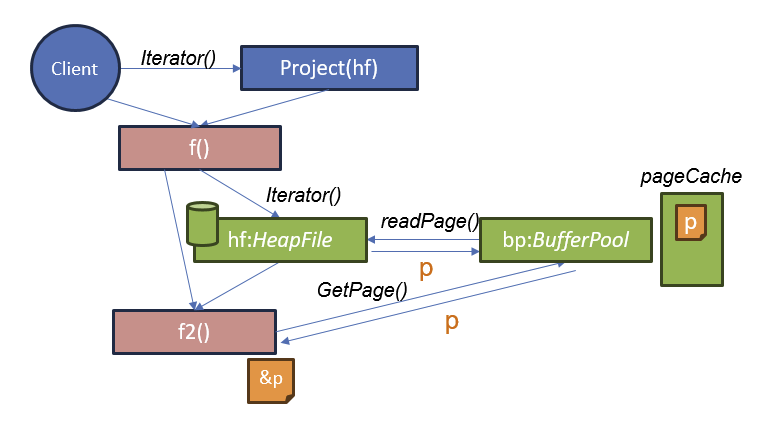
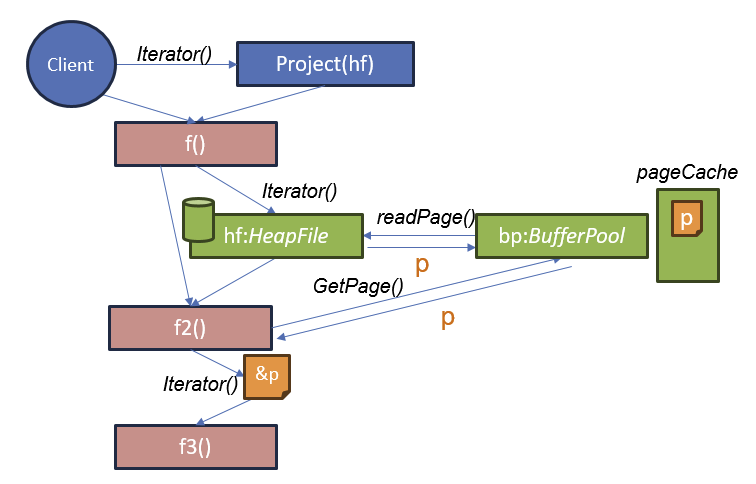
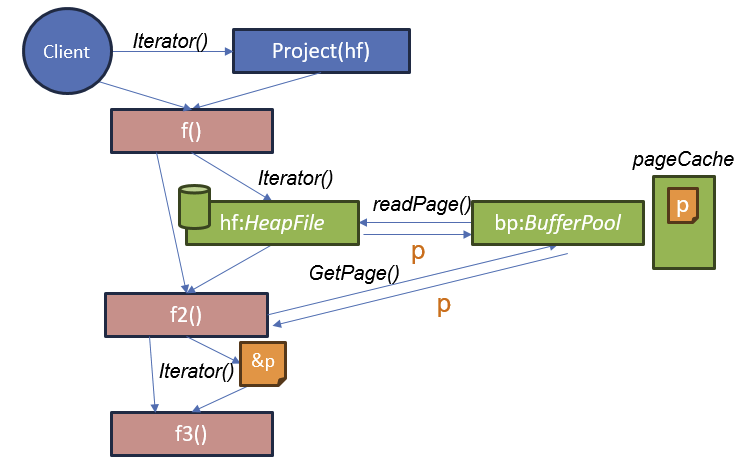
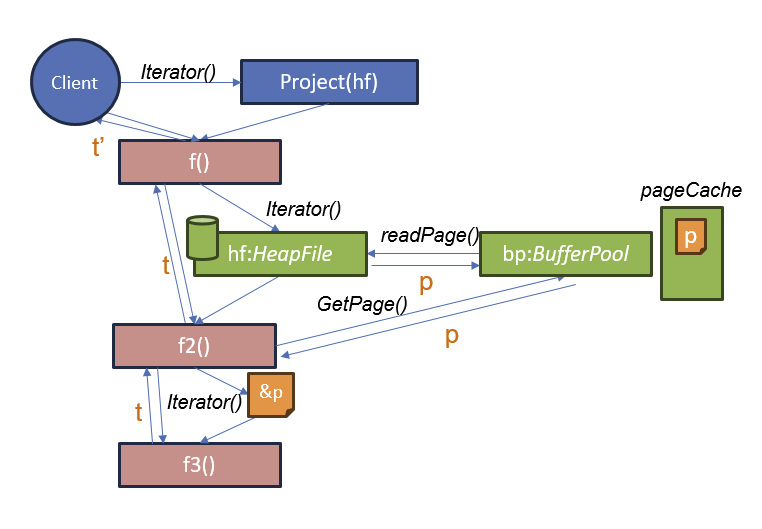
删除记录和记录标识符(RIDs)
考虑如下查询
DELETE FROM x Where f > 10会被转换成如下计划:
堆文件 --> 过滤器 --> 删除
删除操作符如何知道要删除哪些记录?
答: 每条从堆文件 (HeapFile) 中获取的记录都会带有一个记录标识符 (RID),该标识符用于确定要删除的记录在堆文件中的位置
func (f *HeapFile) deleteTuple(t *Tuple, tid TransactionID) error {
// todo
}- delete Tuple 方法将由删除操作符调用。
- 使用 t.Rid 对象,可以清除堆文件中包含该记录的位置。
- 堆文件的实现会在迭代器中提供 Rid,因此可以通过任何方式来标识这个位置。
- 标准的 Rid 实现是页码和页内的插槽号。
- 请记住,所有页面都有相同数量的插槽。

相关课程
CMU
15-445/645 — INTRO TO DATABASE SYSTEMS
15-721 — ADVANCED DATABASE SYSTEMS
15-799 — SPECIAL TOPICS IN DATABASE SYSTEMS
Lec 1 介绍数据库 & 关系模型 & SQL(Part I)
Lec 2 SQL(Part II)
Lec 3 Schema设计
阅读资料:
1、 Section 3.2 and 3.3 of "A Practical Introduction to Databases“
2、 Section 2 of of "A Practical Introduction to Databases"
第一篇阐述了Ted Codd提出的“关系代数”,我们将在讲座开始时讨论这一内容,以及基于函数依赖概念的形式化模型,该模型可以用来推理关于模式是否存在导致数据库系统执行中操作问题的异常。您应专注于理解BCNF和3NF;我们不会讨论更高的范式
第二篇讲述了ER建模,这是一种实际的方法,可以用来建模数据库并生成关系数据库模式。这些阅读的关系在于,ER建模通常会生成符合3NF/BCNF的关系模式,尽管这并非绝对
请考虑并准备在讲座中回答以下问题:
- 模式归一化解决了哪些问题?您认为这些问题重要吗?
- BCNF和3NF之间有什么区别?是否有理由更偏好其中之一?
- 想象您最近处理过的数据集,并尝试推导出相应的函数依赖关系集合。在以这种方式对数据建模时,您需要做出什么假设?
- ER建模通常如何导致BCNF/3NF模式?
Outline
- 关系代数
- 规范化
- 数据模型
Lec 4 数据库内部的介绍
阅读资料:
- Joseph Hellerstein and Michael Stonebraker. Architecture of a Database System, 2007)
- [Architecture of a Database System(中文版) (xmu.edu.cn)](https://dblab.xmu.edu.cn/wp-content/uploads/old/files/linziyu-Architecture of a Database System(Chinese Version)-ALL.pdf)
我们的目标是关注整体系统设计
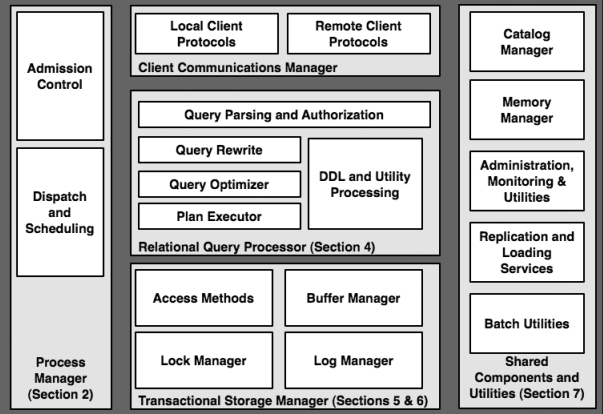
Outline
- 一个查询的来龙去脉
- 进程模型
- 并行架构: 进程和内存协调
- 关系查询处理器
- 存储管理
- 事务:并发控制和恢复
- 共享组件
Lec 5 数据库存储管理
我们专注于面向磁盘的DBMS架构,至顶向下存储层次中,离CPU越近速度越快,但是空间更小, 且单位成本更高。
先Outline面向磁盘的DBMS。数据库完全在磁盘上,数据库文件的数据被组织成页(pages),第一页为目录页。为了操作数据,DBMS需要将数据搬到内存,它通过缓冲池(buffer pool)来管理数据从磁盘到内存的来回搬动。DBMS有一个执行引擎用来执行查询(queries),执行引擎会询问缓冲池特定页面,缓冲池会小心地将页数据带过来,并给到执行引擎指向内存中该页的指针。缓冲池管理器会确保执行引擎在这部分内存操作时,页仍然保持在那。
Outline
有两个主线问题
- DBMS如何表示用磁盘上的文件来表示数据库?
- DBMS如何管理内存,以及从磁盘上往返移动数据的?
分为7个部分讲解
- OS vs DBMS的存储管理
- 文件存储
- 页的布局
- 元组的布局
- 结构化日志存储
- 数据表示
- 系统目录
Lec 6 内存管理
数据库管理系统(DBMS)负责管理内存并协调数据在磁盘与内存之间的双向传输。由于在绝大多数情况下,数据无法直接在磁盘上被操作,因此任何数据库都必须具备高效迁移数据的能力——即将以文件形式存储于磁盘中的数据加载至内存以供使用。图1展示了这一交互过程的示意图。
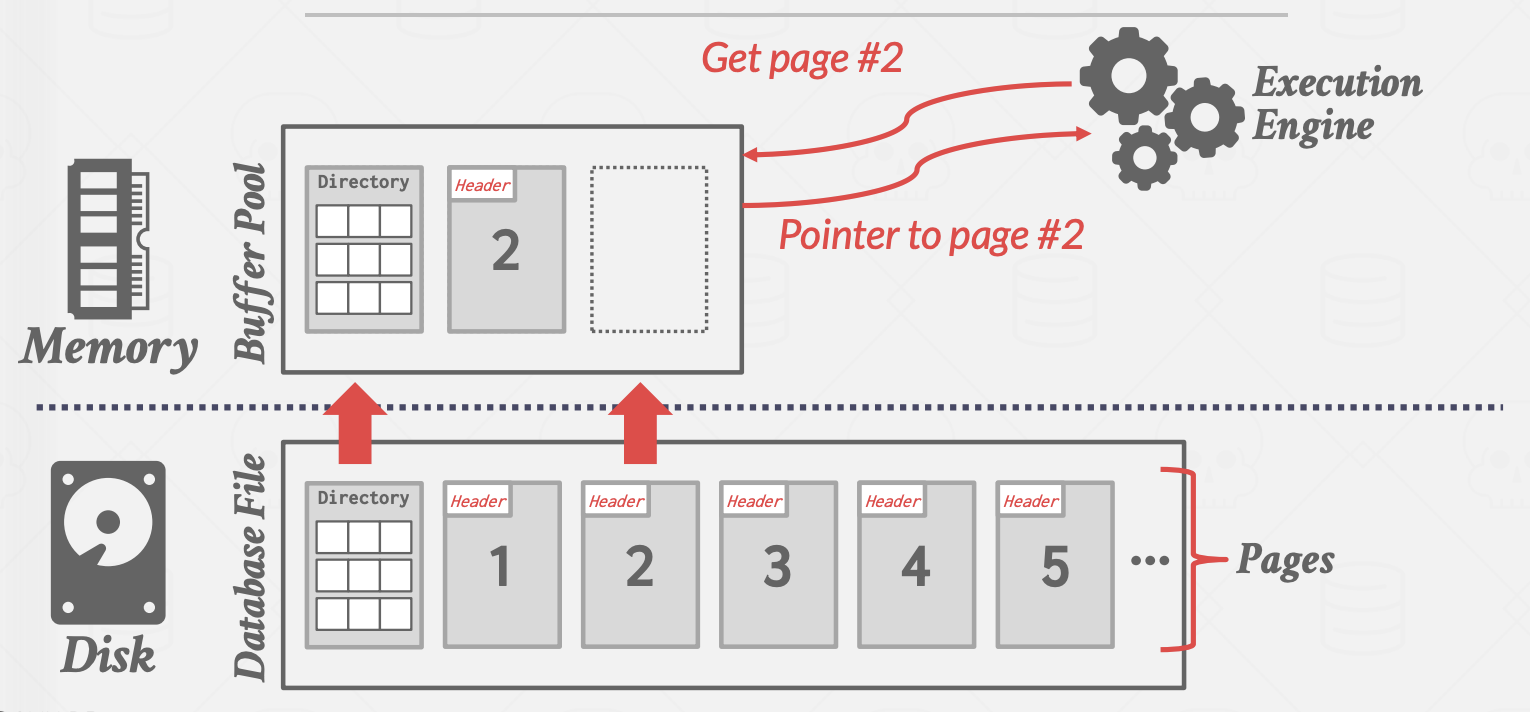
(上图中,执行引擎获取页号为2的页面,如果在缓存池中不存在,则需要通过磁盘中找到相应的页面读入磁盘)
从执行引擎(execution engine)的角度来看,理想情况下应实现**"数据全内存化"的透明访问**,即引擎无需关心数据如何被载入内存,所有数据应如同始终存在于内存中一般可被直接操作。
另一种理解该问题的视角是通过空间控制(Spatial Control)和时间控制(Temporal Control)来分析:
空间控制角度涉及将页面写入磁盘的哪个位置。
- 其目标是将经常一起使用的页面尽可能靠近地存储在磁盘上。这样的话可以减少随机访问,相对增加顺序访问
时间控制角度涉及何时将页面读入内存,以及何时将页面写入磁盘
- 目标是最小化由于需要从磁盘读取数据而导致的停顿次数
Outline
- 锁和闩锁
- 缓冲池
- 缓冲池优化
- 驱逐策略
- 其他缓冲池
- 操作系统页缓存
- 磁盘I/O调度
Lec 7 索引和访问方法
阅读资料:
[B-Tree Basics](https://mit.primo.exlibrisgroup.com/discovery/openurl?institution=01MIT_INST&rfr_id=info:sid%2Fprimo.exlibrisgroup.com-safari&rft.au=Alex Petrov&rft.btitle=Database Internals&rft.date=2019-10-02&rft.eisbn=9781492040347&rft.genre=book&rft.isbn=1492040339&rft.pub=O'Reilly Media, Inc&rft_dat=9781492040330<%2Fsafari>&rft_val_fmt=info:ofi%2Ffmt:kev:mtx:book&svc_dat=viewit&url_ctx_fmt=info:ofi%2Ffmt:kev:mtx:ctx&url_ver=Z39.88-2004&vid=01MIT_INST:MIT). 阅读第2章
The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles pdf
索引(index)和(数据)访问方法(Access Method)
思考问题
- 在什么情况下,二级索引优于堆文件的顺序(按顺序)扫描?在什么情况下,二级索引扫描更可取?
- 在B+树中邻居指针的目的是什么,什么情况下他们有用?
- 为什么B+树不足以存储和索引由R*树存储的数据类型。
Outline
索引
- 聚簇索引 vs 聚簇索引
访问方法
堆文件/堆扫描
Hash索引/索引查找
B+树索引/索引扫描
TODO
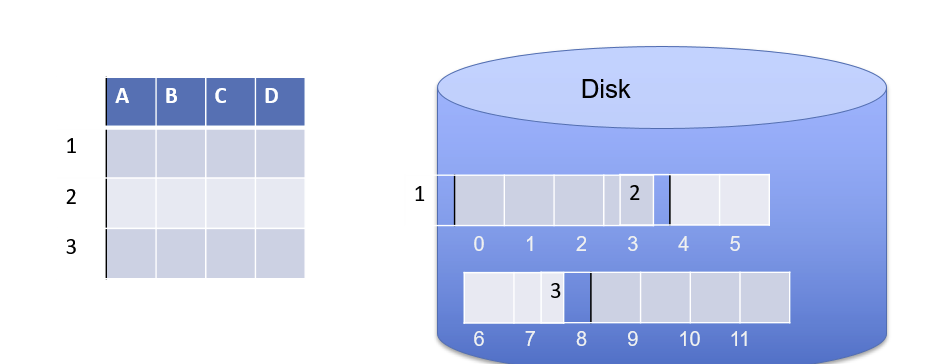
表结构类似如图
A B C D
1
2
3磁盘和内存是线性的,表是2维的,如何在磁盘上存储呢?
- 行优先——一次存储一行
- 列优先——一次存储一列
行优先例子
列优先例子
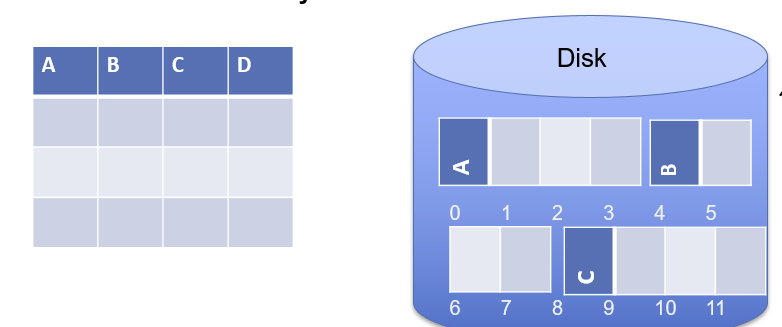
我们后面以行优先存储为主。
而且需要高效的支持插入,删除并且某些记录被读取的频率比其他记录高,该怎么办?
回答这个问题,需要了解如何访问数据的。
查询处理
然后进行验证,优化成为一个程序数 据流执行计划,并且在获得准入许可以后可以代表一个客户程序执行数据流程序。然后,客 户程序获取(“拉”)结果元组,通常一次一个元组或一小批元组。
我们关注查询处理器和“存储管理器的存取方法 的一些非事务处理方面”。关系查询处理可以被看作是一个单用户、单线程任务。
并发控制是由系统较低层透明控制的。这个规则唯一的例外就 是,当 DBMS 操作缓冲池页面的时候,DBMS 必须明确“固定”(pin)和“不固定”(unpin) 缓冲池页面,这样就可以使它们在简短并且关键的操作执行时驻留在内存中,
查询解析和授权
查询处理的步骤
- 授权
- 查询重写
- 查询计划生成(也称计划制定)(SQL->Tree)
- 查询优化
连接操作符: 迭代器模型
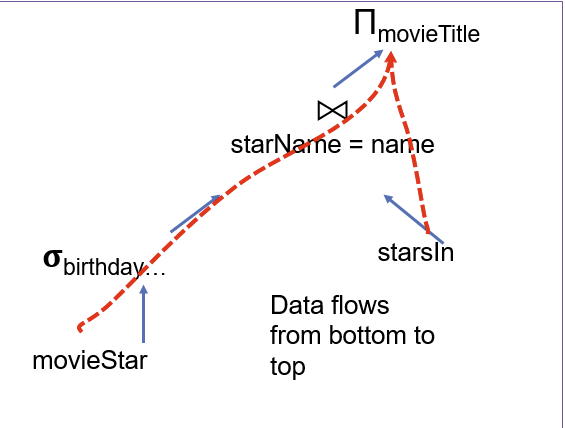
每个操作符都实现了一个简单的迭代器接口:
- open(params): 初始化操作,接收参数并准备执行操作
- getNext() -> record: 获取下一个记录
- close(): 清理操作释放资源
任何迭代器都可与其他迭代器组合使用,形成一个操作链。
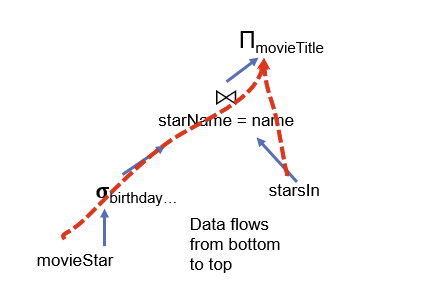
it1 = Scan.open("movieStar", ..) # 从movieStar表中获取数据
it2 = Filter.open(it1, bday=x, ...) # 基于生日为x过滤it1扫描器返回的结果
it3 = Scan.open("starsin", ..) # 从starsin表中获取数据
it4 = Join.open(it2, it3, starName=name) # 联接两个表
it5 = Proj.open(it4, movieTitle) # 投影返回movieTitle字段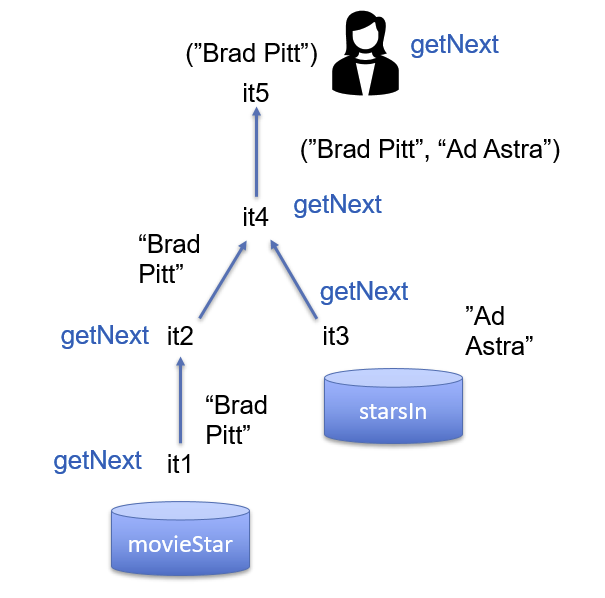
具体代码实现,GoDB为例
hf1,_ := NewHeapFile(MovieStarsFile,..)
filt, _ := NewIntFilter(&ConstExpr{IntField{..}, IntType}, OpGt, &fieldExp, hf1)
hi2,_ := NewHeapFile(StarsInFile,...)
join, _:= NewStringEqJoin(filt, &leftField, hf2, &rightField, 100)
proj, _ = NewProjectOp([]Expr{&fieldExpr}, outNames, false, join)
iter, _ := proj.Intertor(tid)
for {
tup, err := iter()
if err != nil { t.Errorf(err. Error())}
if tup == nil {
break
}
// do something with tup
}一个好的查询计划是需要什么?
代价评估
代价评估Cost Estimation
查询优化的目的是什么?
找到具有最低成本的执行计划
什么是代价?
- 磁盘I/O(读取的页数)
- 内存访问次数
- CPU周期
- 比较次数
- 处理的记录数
存储层次

- 对于易损性存储器(Primary Storage),我们用通过随机访问(可以按字节编址)。我们将主存简称为内存"memory"
- 而对于非易损性存储器(Secondary Storage),我们通过顺序访问(按块来编址)。我们将这个层次的存储器统称为disk。
从计算机架构下的存储层次
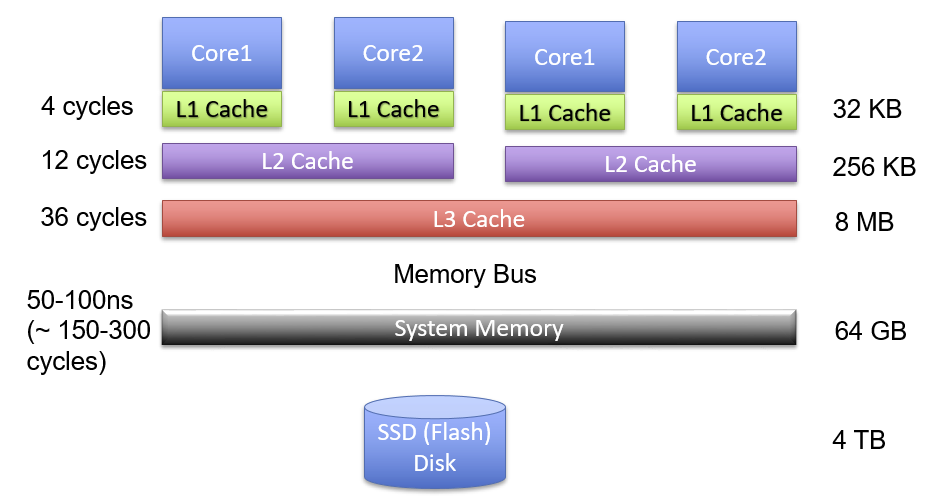
访问时间——一组重要数据
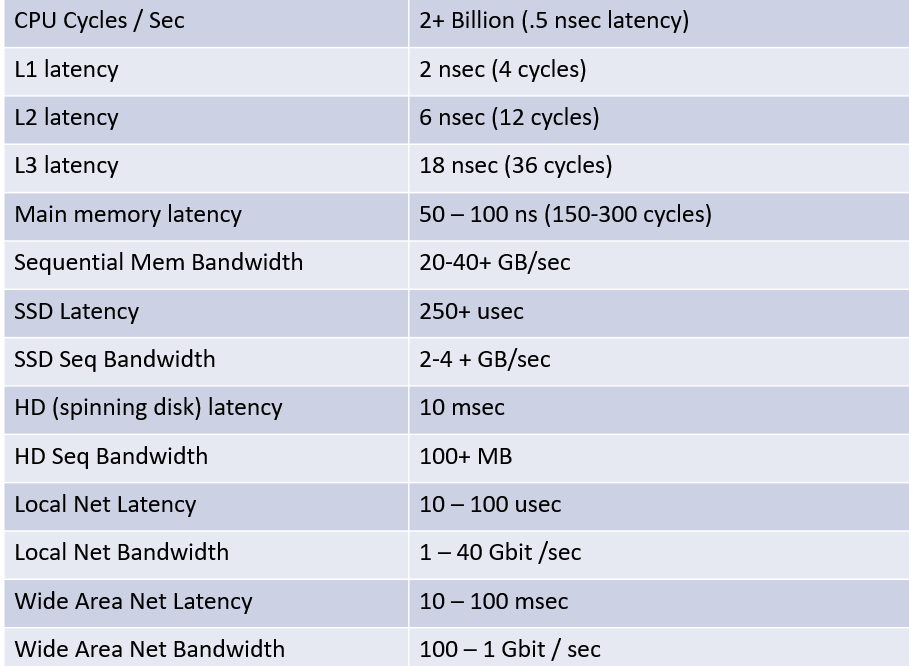
- L1 到 主存 大 2个 数量级
- L1->L2->L3 是 3倍增长,并且L1访问一次需要4个机器周期
- 主存->SSD->HDD 2个数量级增长
- 本地网络高速网络可能比SSD性能还要好上两倍到一个数量级?
顺序访问 vs. 随机访问
在非易损性存储上,随机访问几乎总是比顺序访问慢。
因此DBMS会最大化顺序访问
- 算法会尽量减少在随机页写的次数,因此数据会存储在连续块里面
- 同时分配多页时,被称为一个区(extent)
因为磁盘读写很贵,因此必须小心的管理以免大规模的停顿和性能下降。
成本估计(TODO)
查询处理步骤
- 准入控制
- 查询重写
- 视图代换
- 谓词转换
- 子查询扁平化
- 生成计划(SQL转成树)
- 查询优化
查询重写
- 视图代换。将视图查询替换为其定义的实际查询
- 谓词转换。修改查询中的谓词(条件),使其更容易优化或更高效地执行。例如,将
OR条件转换为UNION操作 - 子查询扁平化。将嵌套子查询转换为联接或其他等价的非嵌套查询
视图代换
# emp: id, sal, age, dept
CREATE VIEW sals as (
SELECT dept, AVG(sal) AS sal
FROM emp
GROUP BY dept
)
SELECT sal FROM sals WHERE dept = 'eecs';
# 代换为
SELECT sal FROM (
SELECT dept, AVG(sal) AS sal -- 将视图sal代换其定义的实际查询
FROM emp --
GROUP BY dept --
) WHERE dept = 'eecs';谓词转换
删除 & 简化表达式,提升性能
常数简化: 如
sqlWHERE sal > 4000 + 1000 ---> WHERE sal > 5000挖掘限制
sqla.did = 10 and a.did = dept.dno ---> a.did = 10 and a.did = dept.dno and dept.dno = 10移除冗余表达式
sqla.sal > 10k and a.sal > 20k ---> a.sal > 20k
子查询扁平化
很多子查询能够被消除
sqlSELECT sal FROM ( SELECT dept, AVG(sal) AS sal FROM emp GROUP BY dept ) WHERE dept = 'eecs'; ----> SELECT AVG(sal) FROM emp GROUP BY dept HAVING dept = 'eecs';但注意不一定都能这样做
看下例子,有四个选项,将下面查询扁平化(查看机器比员工多的部门)
SELECT dept.name
FROM dept
WHERE dept.num_machines >=
(SELECT COUNT(emp.*)
FROM emp
WHERE dept.name=emp.dept_name)
答案是 D
生成计划(SQL->Tree)
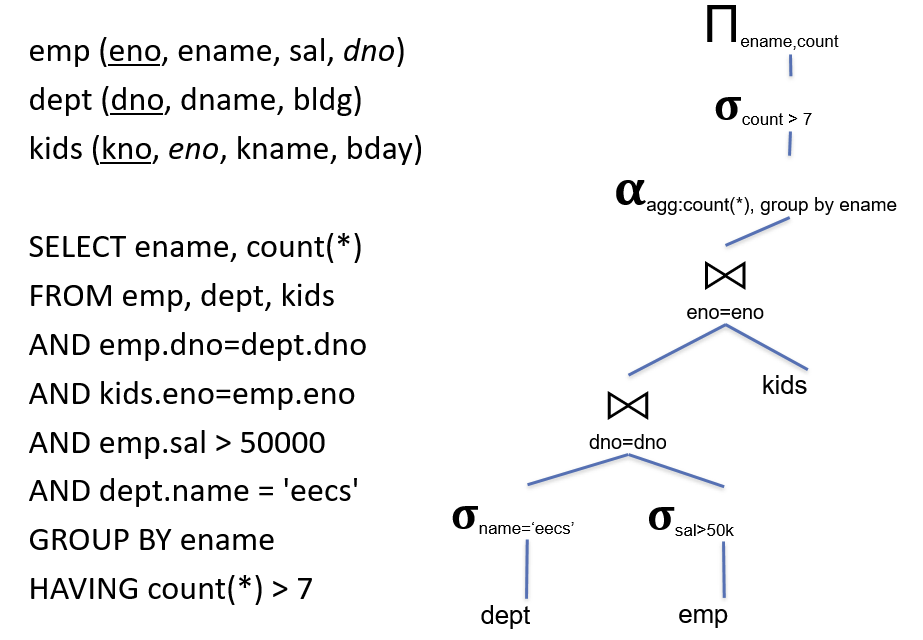
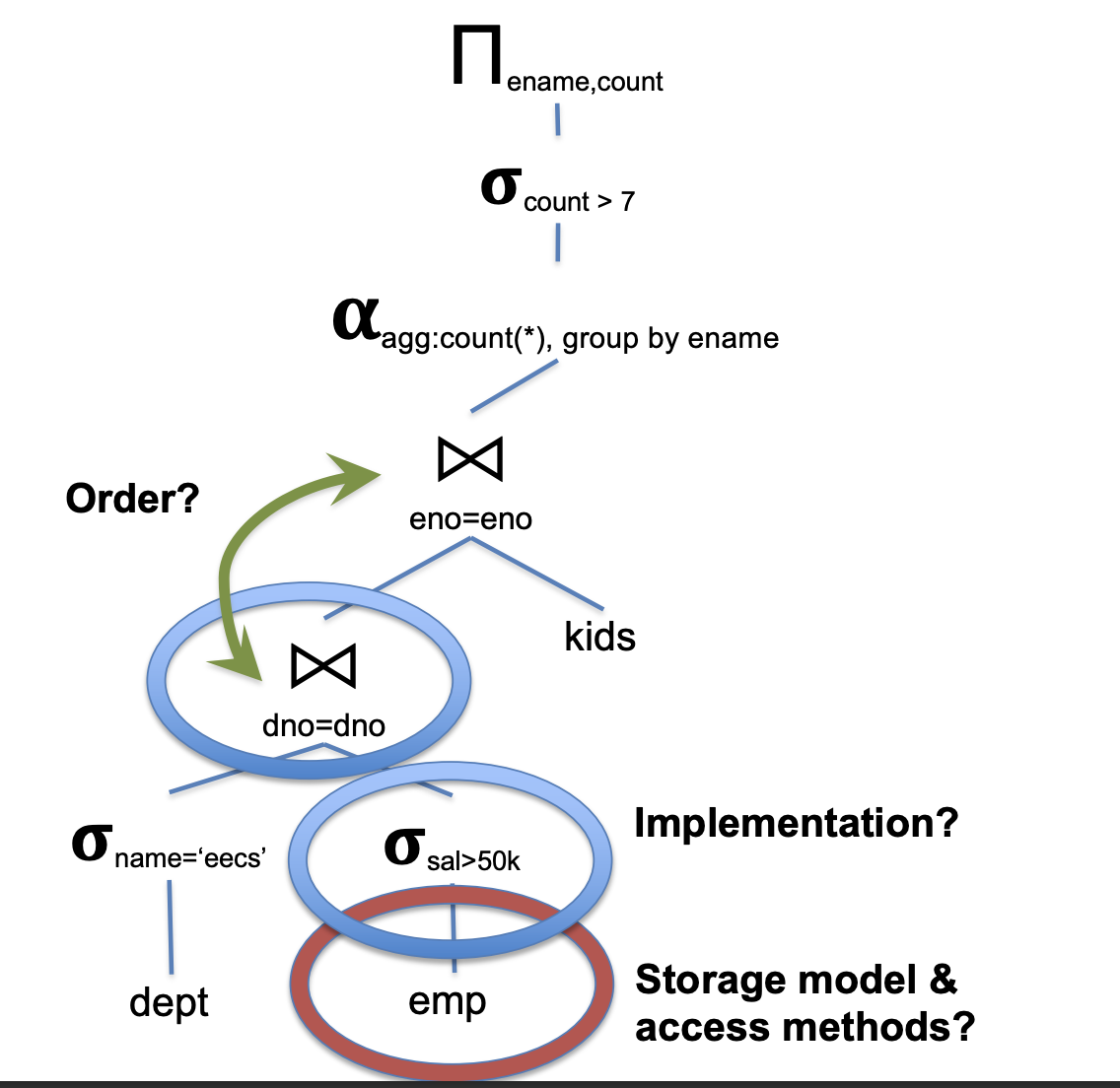
查询优化
分为逻辑优化和物理优化
- 物理优化: 运算符实现和存取方法的选择(索引 vs 堆文件)
- 逻辑优化: 运算符的排序(搜索空间为指数级别)
Joins 和 Ordering
考虑一个嵌套循环的Join连接符号,它连接表Outers 和Inner
for tuple1 in Outer
for tuples in Inner
if predicate(tuple1, tuple2) then
emit join(tuple1, tuple2)如果Inner本身是一个连接结果怎么办?
计划可能变成"left-deep" 或者 "bushy"
- 左深(left-deep):这种计划将连接操作链成一个从左到右的线性结构,意味着每个连接的结果将立即用于下一个连接操作。
- 丛状(bushy):这种计划允许更复杂的结构,其中某些连接结果可以并行计算,而不是线性依次进行。
查询执行
执行一个查询涉及到将一系列的操作连接起来
操作的类型:
- scan 从磁盘或者内存扫描(需要数据表示模型)
- filter 记录
- join 记录
- aggregate 记录
Lec 8 Join算法
阅读资料
参考书 Chapter 15.4-15.6
Join Processing in Database Systems with Large Main Memories, 1986
良好的数据库设计是为了最小化信息冗余,这正是基于规范化理论构建表结构的原因。重点研究用于双表组合的内等值连接算法。等值连接算法通过匹配键值相等的记录来合并表数据,这些算法经过调整后也可支持其他类型的连接操作。特别关注Hash Join 和Sort-Merge join连接,以及这两种方法权衡。
Lec 9 查询计划 & 优化
阅读思考题
Selinger论文声称是“最优的”。在什么假设下这种最优性成立?你能想到Selinger方法肯定会非最优的情况吗?
查询优化高度依赖于成本估算的有效性。Selinger提出的成本度量非常简单;你如何使它们更加复杂?更复杂的成本度量对数据库系统性能有什么影响?
Lec 10 查询计划 & 优化
阅读资料
- 《Database System Concepts, 7th edition》 Chapter 16
- 参考书小红本 Access Path Selection in a Relational Database Management System. SIGMOD'1979) 第 22-34 页内容
- (可选) Statistical Profile Estimation in Database Systems, 1988
当数据库接收到一个查询时,查询优化器(Query optimizator)会尝试从众多策略中选择最高效的的查询执行计划(Query-evaluation plan,QEP)。优化的一个方面发生在代数关系级别,系统尝试找到与给定表达式等价但执行效率更高的表达式。另一个方面是选择处理查询的具体策略,例如选择用于执行操作的算法、选择要使用的特定索引等等。
查询执行计划(QEP)的好坏直接影响到查询的执行效率。为了选择最优的执行计划,优化器需要估算每个步骤(如表扫描、连接、过滤等)的结果集大小,也就是“基数”。基数估计不准确会导致次优甚至糟糕的执行计划,从而影响性能。
Outline
- 估算单表的基数
- 直方图(被PostgreSQL采用)
- 处理相关列
- 特殊过滤类型和估算方法
- 估算连接操作的基数
- 均匀性假设
- 连接直方图
- 近期进展
Lec 11 分析数据库的布局
阅读材料
C-Store: A Column Oriented DBMS, 2005
Column-Stores vs. Row-Stores: How Different Are They Really?, SIGMOD'08
我们将讨论面向列的数据库,它代表了构建关系数据库的不同方式,该数据库针对大规模的读密集型操作进行了优化,而非对事务处理的优化。
数据库的工作负载可以分为以下3种类型:
- OLTP, Online Transactional Processing,联机事务处理。OLTP 负载的特点是操作快速、运行时间短、重复性高,查询通常很简单,并且每次只作用于一个实体。 这类负载通常写多读少,每次只读取或更新数据库中的少量数据。
- 一个 OLTP 负载的例子是 亚马逊的前台商店系统:用户可以将商品加入购物车并进行购买,但这些操作只影响他们自己的账户。
- OLAP, Online Analytical Processing,连接分析处理。OLAP 负载的特点是运行时间长、查询复杂,通常会读取数据库中很大一部分数据。这类负载通常用于分析或从 OLTP 系统收集的数据中推导出新信息。一个 OLAP 负载的例子是:亚马逊统计某个下雨天,匹兹堡地区最畅销的商品是什么。
- HTAP , Hybrid Transactional and Analytical Processing(HTAP),混合事务与事务处理。HTAP 是一种新型的数据库负载模式(近年来越来越流行),它将 OLTP 和 OLAP 的负载整合在同一个数据库系统中。
Lec 12 事务和锁
阅读资料
本章开始我们讨论下并发控制和恢复,如何保证更新和数据库故障时保持正确性
Lec 13 乐观并发控制与快照隔离
阅读资料:
继续学习并发控制,这节Lec将学习另外一种隔离事务的方法——乐观并发控制(Opitimistic Concurrency Control, OCC)
阅读过程中回答下面问题:
- 你认为在什么情况下,乐观并发控制会比基于锁的并发控制表现更好?
- 乐观并发控制会导致死锁吗?
- 你会如何在SimpleDB中实现乐观并发控制?
Outline
Lec 14 故障恢复(Part I)
阅读资料
ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging, 1992 ,读1-7节,泛读12和13节
恢复算法(Recovery algorithm)是保证数据库一致性、事务原子性和持久性的技术,当crash发生时,所有存在于内存但未提交到磁盘的数据将会丢失。恢复算法发挥崩溃后组织信息丢失的作用,每个恢复算法包含两个部分:
- 在正常事务处理期间保证DBMS能从故障中恢复的动作
- 在故障发生后,将数据库恢复到能够保证原子性、一致性和持久性的状态。
在恢复算法中最关键的两个原语是 UNDO 和 REDO。
这是一篇冗长且难度较高的论文,我们将在两次讲座的大部分时间里探讨它。重点理解ARIES恢复算法的核心。
故障恢复的难点
- B树
- 逻辑插入创建不同的B树
- 在更新多页B-树或B-树与数据页不一致时崩溃
- 检查点成本
- 在执行检查点操作时,我们是否必须阻塞系统?
- 恢复时间
- 在系统再次可用之前,我们需要等待多久?
- 恢复期间崩溃
- 在执行恢复过程中,如果系统再次崩溃,会发生什么?
- 托管更新(Escrow updates)
- 托管更新是指某些事务可能需要保留某些资源的部分更新,在恢复过程中处理这些更新可能会非常复杂。
大纲
- 日志记录的黄金准则
- 指定所有细节
- NO Force / Steal
- 可恢复的故障恢复
- 日志记录的哲学
- 低开销的checkpoint
- 支持托管更新
- E.g., increment / decrements
Lec 15 分布式数据库
Outline
IMPORTANT
- 并行数据库: 研究如何让多个处理器/机器来执行一个SQL查询的不同部分。
- 特别适用于大规模、运行缓慢的查询
- 分布式数据库:当这些机器物理上分离并独立故障时会发生什么
- 特别适用于事务处理
- 并行架构
- 并行查询处理
- 并行操作
- Join策略
- 并行策略
Lec 16 分布式事务
为了解决在share-nothing的环境中提供类ACID的语义的问题,我们探讨分布式事务。
阅读资料
Transaction Management in the R* Distributed Database Management Systems, 1986
- 介绍2PC协议的扩展版本。引入了“假定中止”(PA,Presumed Abort)和“假定提交”(PC,Presumed Commit)。PA 针对只读事务和某一类多站点更新事务进行了优化,而 PC 则对其他类别的多站点更新事务进行了优化。这些优化减少了站点间的消息传输和日志写入,从而提升了响应时间
Lec 17 最终一致性
在本课程中,我们将探讨一系列“NoSQL”数据库系统,这些系统提供与关系数据库系统不同的事务一致性属性、查询语言。上述两篇阅读材料描述了亚马逊的一个有影响力的NoSQL系统——“DynamoDB”,以及亚马逊首席技术官对最终一致性支持的关键思想的讨论
Lec 18 集群计算:Spark
阅读资料
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. nsdi‘2012 [PDF]
这节Lecture,我们讨论Spark,一种集群计算语言,与MapReduce有类似的设计目标,但是在性能、缓存、可编程性上有所提升。我们已经学习了各种各样的DB,数据分析为主的C-store数据库、事务处理为主的H-store数据库、高可用的DynamoDB、云化的AuraraDB等等,本节我们将学习一个新的,针对数据科学(data science)而生的数据系统Spark
边阅读边思考一下问题:
- Spark计算模型和MapReduce相比有什么相似的?有什么区别?
- 什么是弹性分布式数据集(RDD)? 如何帮助程序员写出容错的程序?
Lec 19 高性能事务
HighPerformance Transactions, 这节课会探讨一下近20年的事务处理的新思路,覆盖了单点和多节点系统,主要聚焦可扩展的分布式事务处理。
- M. Stonebraker, S. Madden, D. J. Abadi, S. Harizopoulos, N. Hachem, and P. Helland. VLDB 2007. The End of an Architectural Era (It’s Time for a Complete Rewrite)
- [Optional] Alexander Thomson, Thaddeus Diamond, Shu-Chun Weng, Kun Ren, Philip Shao, and Daniel J. Abadi. SIGMOD 2012.Calvin: fast distributed transactions for partitioned database systems.
- [Optional] Yi Lu, Xiangyao Yu, Lei Cao, Samuel Madden. VLDB 2021. Epoch-based Commit and Replication in Distributed OLTP Databases
Lec 20 SnowFlake
阅读材料
本章我们会讨论Snowflake, 一种专为云端设计的数据库
The Snowflake Elastic Data Warehouse, SIGMOD'16
思考题思考
- 为了云化,SnowFlake用了什么方法?
- 如何做到弹性伸缩(scale "elastically")?
- SnowFlake有一个共享盘(shared disk)设计。有什么好处? 有什么不足?