6.1910 计算结构
先行条件
(无)
课程描述
本课程介绍数字系统与计算机体系结构的设计方法,重点强调使用高级硬件描述语言(HDL)表达硬件设计并完成综合(synthesizing)。主要内容包括:
- 组合逻辑与时序电路
- 可编程硬件的指令集抽象
- 单周期与流水线处理器实现
- 多级存储层次(缓存、主存等)
- 虚拟内存机制
- 异常处理与输入/输出(I/O)系统
- 并行计算体系结构
参考书
- 《Digital Design: A Systems Approach》 2012
- 《计算机组织和设计: 软硬件接口,RISC-V版》 2017
- MIT自己计算结构在线材料

课程内容
模块一: 数字系统设计(组合和时序电路)
- 二进制的表示和运算
- RISC-V 指令集
- RISC-V汇编语言编程
- 用汇编语言表示高级语言
- 过程调用约定
模块二: 计算机架构(汇编语言、处理器、缓存和流水线)
数据抽象
boolean 运算和组合逻辑
时序逻辑
用Bluespec表达逻辑设计,一种现代的硬件设计语言
逻辑语法
流水线和折叠电路
实现非流水线RISC-V计算机
Cache
实现流水线RISC-V计算机
- 控制冒险和数据冒险,旁路技术
分支预测
模块三: 计算机系统(OS、VM、I/O)
- 操作系统
- I/O中断和异常
- 虚拟内存
模块四:并行编程和多核问题
- 同步
- 缓存一致性
学习目标
完成后,期望你能掌握
- 理解抽象在大型数字系统设计中的作用,并能阐述现代计算机系统中的主要软硬件抽象层次。
- 运用延迟(latency)和吞吐量(throughput)等指标分析数字系统性能。
- 基于多种数字抽象方法设计简单硬件系统,包括:
- 只读存储器(ROM)与逻辑阵列
- 逻辑树
- 状态机
- 流水线
- 总线
- 通过组件库综合数字系统,并在仿真环境下测试设计。
- 深入理解中等复杂度数字系统(基于简易RISC架构的计算机)的运作机制,直至门级实现,具备其组件的综合、实现与调试能力。
- 掌握数字系统工程师所需的核心技术能力。
Labs
- 组合电路
- ALU设计
- 时序电路
- 处理器实现
- 设计Cache
- Pipelined 处理器
- OS
相关课程
UC伯克利: Home | CS 61C Spring 2024
CMU: CMU 18-447 Introduction to Computer Architecture – Spring 2015] (cmu.edu)
Module 1 数字逻辑设计
- 布尔计算
- 组合电路
- 时序电路
- 用Bluespec表达逻辑电路
- 逻辑综合:
- 从Bluespec 到逻辑电路
- 从逻辑电路到标准的门电路库
- 并发问题
Lec 1 数字系统抽象
这门课的聚焦点是: 设计通用处理器。
通用处理器,意味着设计出能上运行Py,Java,C等高级语言的硬件,这是一个挑战,对于执行的任何一个高级语言的特性对于硬件来说,并不敏感。机器码是软件-硬件之间的接口约定
微处理器是构建计算机系统的基本块: 即便你不从事硬件设计,但是理解他们的工作原理对于程序员来说也是很重要的。微处理器是世界上最复杂的数字系统:理解它能够帮助你设计各种各样的硬件。
本课程依赖的工具:minispec, 简化版的Bluespec SystemVerilog(BSV)。我们用一个高级的编程语言来表达设计,它最终会被编译产生电路描述。
一个观点——即使我们将来在职业生涯中不从事硬件的构建,我们可能仍然会设计一些尖端系统,因此我们需要具备良好的硬件知识。更重要的是,在现代社会中,系统变得越来越专业化。通用处理器的性能改进正在达到极限——如果我们回顾自80年代以来处理器的性能,我们已经取得了惊人的的(50000倍)提升,主要是首先遵循摩尔定律(告诉我们可以在芯片上拥有指数级数量的晶体管),然后是德纳德缩放。但在目前,这种性能改进基本上已经停止,公司现在开始构建定制硬件以满足他们的需求。因此,我们可能需要使用和设计专用硬件,而不仅仅依赖于通用处理器。
Outline
- 数字信号系统
- 电压转换特性
Lec 2 组合逻辑设备和布尔算术
组合逻辑设备(combinational device)是一种电路器件满足:
- 一个或多个输入
- 一个或多个输出
- 功能规范(functional specfication),必须明确定义所有可能输入组合对应的输出值。
- 时序规范(Timing Specification),必须指定传播延迟,从输入稳定到输出稳定的最长时间上限。确保器件在
内完成计算并输出有效结果
上述四个标准统称为静态准则,是所有组合逻辑器件必须满足的基本要要求。

功能规范,有不少方法用于详述组合逻辑设备的功能规范。我们将使用两种系统性方法:真值表和布尔表达式(boolean expression)
Outline
- 布尔算术
- 从布尔算术到门电路
- 总结
TODO
Instruction Set Architecture(ISA)
ISA:指令集架构是软件和硬件之间的协议
- 功能定义和存储位置
- 软件如何调用和访问他们的精准描述
RISC-V ISA:
- 伯克利开发的船新的,开源免费的ISA
- 有几种改版
- RV32、RV64、RV128: 不同的数据宽度
- “I”: 基础整数指令集版
- "M": 乘除法扩展版
- "F" and "D": 单或双精度浮点数
- 我们会使用RV32I 处理器,基于 base integer 32-bit 的版本
RISV-V 处理器的存储
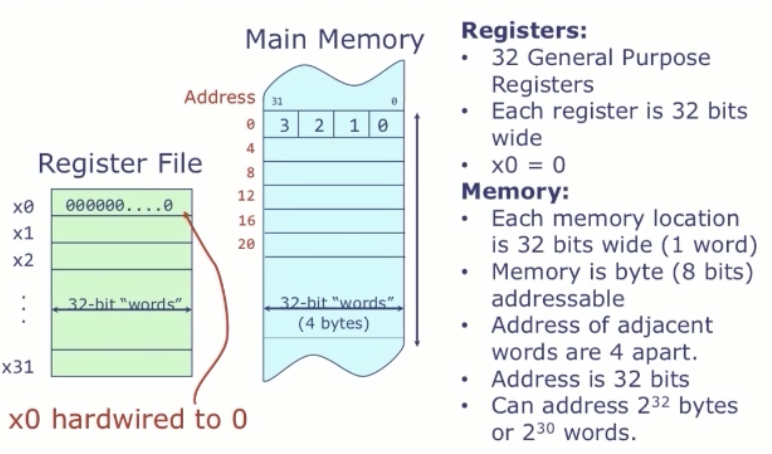
x0硬连线道常量0,因此任何时候访问x0,你都会读到0,如果你往上面写数,相当于啥事也没干。
指令的类型
- 算术和逻辑操作
- 存取操作
- 控制流操作
算术和逻辑操作
包括算术、比较、逻辑和移位操作。
寄存器-寄存器型指令
- 2个源操作数寄存器
- 1个目标寄存器
| 算术 | 比较 | 逻辑 | 移位 |
|---|---|---|---|
| add, sub | slt, sltu | and, or,xor | sll, srl, sea |
格式: oper dst, src1, src2
几个例子
assemblyadd x3, x1, x2 # x3 <- x1 + x2 slt x3, x1, x2 # if x1 < x2 then x3 = 1 else x3 = 0 sll x3, x1, x2 # x3 <- x1 << x2
slt 意思是 set less than
sll 意思是 set left logical
二进制模算术(Modular Arithmetic)
当你在加法或者其他操作中出现溢出时,通用的做法是忽略额外的位。
对于两个二进制数 a 和 b,在模 n 的情况下,加法运算如下:
(a+b) mod n
例如,模 8 系统中的加法:
- a=5 (二进制:101)
- b=3 (二进制:011)
加法结果:
(5+3)mod 8 = 8 mod 8 = 0
二进制运算
101 + 011 = 1000
结果是8,在模8系统中,8相当于0
十六进制表示法
如果用长的比特串容易犯错,因此我们通常用higher-radix表示,就是半径比较大的圆,这样也容易将数恢复成bit串,一个常用的选择是base-16,叫十六进制表示法(hexadecimal),每个4个bit为一组,编码成十六进制的一个字母
寄存器-立即数指令
一个操作数来自寄存器,另一个是一个小的常数。
格式为: oper dst, src1, const
addi x3, x1, 3
andi x3, x1, 3
slli x3, x1, 3注意没有 subi
我们可以用负数代替
addi x3, x1, -3复合计算Compound Computation
执行 a = ((b+3) >> c) - 1;
- 将复杂的表达式拆分,我们的指令仅仅能支持两个源操作数和一个目标操作数
- 假设a, b, c在寄存器x1, x2,和x3,相对的,我们用x4代表t0, x5代表t1
t0 = b + 3;
t1 = t0 >> c;
a = t1 - 1;
addi x4, x2, 3
srl x5, x4, x3
addi x1, x5, -1控制流指令
if (a < b): c = a + 1
else: c = b + 2格式: comp src1, src2, label
- 第一个比较决定if分支是是否接受: src1 comp src2
- 如果比较返回True,那么分支就被接受了,否则继续执行
| 指令 | beq | bne | blt | bge | bltu | bgeu |
|---|---|---|---|---|---|---|
| comp | == | != | < | >= | < | >= |
# 假设 x1 = a; x2 = b; x3 = c;
bge x1, x2, else # 注意,是a >= b时候跳else
addi x3, x1, 1
beq x0, x0, end #
else: addi x3, x2, 2
end:无条件跳转指令
jal: Unconditional jump and link(后面会讲)
- 格式:jal x3, label
- Jump target specified as label
- 标签被编码为当前指令的偏移量
- Link:is stored in x3
jalr: Unconditional jump via register and link
- 格式: jalr x3, 4(x1)
- 跳转的目标指定为寄存器的值加上常数偏移量
- Ex: Jump target = x1 + 4
- 能够跳转到任何32位的地址-support long jumps
# 伪指令
j label
# 等同的汇编指令
jal x0, label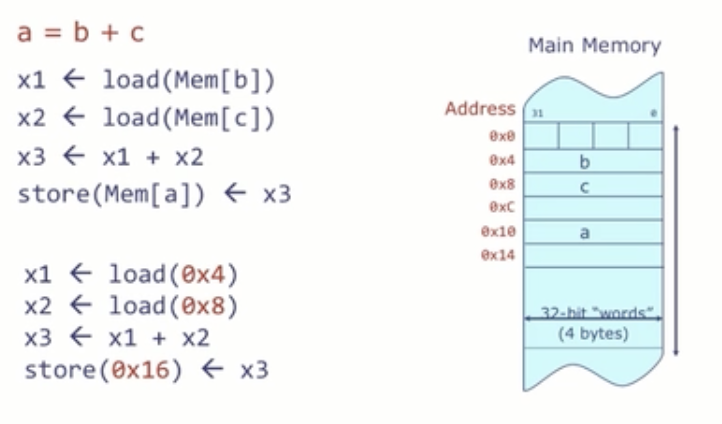
RISV-V 存取指令
- 由于一些原因,RISC-V ISA不允许我们直接在指令写入内存地址。
- 地址用<base address, offset>对表示
- 其中base address总是被保存在一个寄存器里面
- offset通常是一个很小的常数
- 格式:lw dest, offset(base) or sw src, offset(base)
# 行为
x1 <- load(Mem[x0 + 0x4])
x2 <- load(Mem[x0 + 0x8])
x3 <- x1 + x2
store(Mem[x0 + 0x10]) <- x3
# 对应的汇编
lw x1, 0x4(x0) # load word
lw x2, 0x8(x0)
add x3, x1, x2
sw x3, 0x10(x0) # 注意顺序累加数组元素
sum = a[0] + a[1] + .. + a[n-1]; 假设x10已经取数100。
lw x1, 0x0(x10)
lw x2, 0x4(x10)
lw x3, 0x8(x10)
loop:
lw x4, 0x0(x1)
add x3, x3, x4
addi x1, x1, 4
addi x2, x2, -1
bnez x2, loop
sw x3, 0x8 (x10)常数和指令编码限制
- 指令都编码成32bits
- 需要指定操作类型(10bits)
- 指定两个源寄存器(10 bits,因为我们有31个寄存器,因此5位就可以表示)或者一个源寄存器(5bit) 加上一个小的常数
- 需要指定一个目标寄存器(5bits)
- 指令中的常数应该在12bits以内,大的常数必须保存在内存或者是寄存器,然后显式使用
- 然而, 小的常数在编程当中非常有用
- 正因为这些限制,我们不能往内存空间直接写入指令。
伪指令
为其他指令提供别称,从而简化汇编编程
# 伪指令
mv x2, x1
ble x1, x2, label
beqz x1, label
bnez x1, label
# 对应的汇编指令
addi x2, x1, 0
bge x2, x1, label
beq x1, x0, label
bne x1, x0, label负数的编码
补码技术(two’s complement encoding )fw6
Lec 3 用Bluespec描述组合电路
算术计算和布尔算术有很强的联系。数字可以用二进制(base 2)来表示,并且能对其进行算术运算。更进一步,二进制的算术运算和布尔代数中的逻辑运算之间存在一一对应关系,比如,二进制加法可以用 XOR 和 AND 实现(比如半加器、全加器)
因此,我们可以把所有的算术操作(像加、减、乘等)用布尔表达式来表示,而这些布尔表达式就可以被实现成组合逻辑电路(combinational circuits)
Outline
- 加法器
- 多路复用器
- 移位器
TODO 编译表达式,函数和栈
处理常数
执行 a = b + 3,常数(12-bit内)能够通过寄存器-立即数的ALU操作执行
- addi x1, x2, 3
执行 a = b + 0x123456
最大12bit补码表示为2^11-1 = 2027(0x7FF)
使用
li(load immediate)伪指令设置寄存器。li x4, 0x123456 对应的汇编为assemblylui x4, 0x123 # load upper immediate,一个20位的立即数加载到寄存器的高20位,而低12位填充为0 addi x4, x4, 0x456同样的我们可以用
li伪指令执行小的常数的操作assembly# 伪指令 li x4, 0x12 # 汇编 addi x4, x0, 0x12
编译简单的表达式
- 指派变量到寄存器
- 将操作翻译成计算指令
- 使用寄存器-立即数指令来执行操作
- 使用li伪指令来执行大常数的操作
int x, y, z;
y = (x + 3) | (y + 123456);
z = (x * 4) ^ y;对应的RISC-V汇编
# x: x10; y: x11; z: x12
# x13, x14用于临时数据
addi x13, x10, 3
li x14, 123456
add x14, x11, x14
or x11, x13, x14
slli x13, x10, 2
xor x12, x13, x11编译条件分支
NOTE
简单的if表达式
C code
if (expr) { if-body }
汇编
(compile expr into xN) beqz nN, endif (compile if-body) endif
例子
int x, y;
if (x < y) {
y = y - x;
}
# 汇编, 假设x:x10, y:x11
slt x12, x10, x11
beqz x12, endif
sub x11, x11, x10
endif:
# 汇编2
bge x10, x11, endif
sub x11, x11, x10
endif:NOTE
If-else 表达式
C code
if (expr) { if-body } else { else-body }
汇编
(compile expr into xN) beqz nN, else (compile if-body) j endif else: (compile else-body) endif:
NOTE
Loop 表达式
C code
while (expo) {
while-body
}
汇编
while:
(compile expo into xN)
beqz xN, enwhile
(compile while-body)
j while
endwhile:
你能够写出执行指令更少的版本吗?
# 只有一个分支或者每个迭代都跳转的版本
j compare
loop:
(compile while-body)
compare:
(compile expr into xN)
bnez xN, loop把上述的都放在一起。
while (x != y) {
if (x > y) {
x = x - y;
} else {
y = y -x;
}
}RISV-V的汇编是什么呢?
# x: x10, y: x11
j compare
loop:
ble x10, x11, else
sub x10, x10, x11
j endif
else:
sub x11, x11, x10
endif:
compare:
bne x10, x11, loop函数调用(Procedures)
可复用的代码段,用于执行指定的任务
- 它只有一个入口
- 零个或若干个形式参数
- 局部变量
- 当执行结束后返回调用者
作用:
实现抽象和复用
Lec 4 二进制计算
Outline
- 二进制运算
- 加法器实现优化
Lec 5 CMOS技术 & 组合电路:从布尔计算到门电路
实验2的目标是设计一个32位的ALU,这是计算机中极为常见的组件。已经见过两位全加器(FA)串联组成的 2-bit ripple-carry adder,如果要扩展成 W 位加法器,该怎么办?今天要讲如何通过循环来描述参数化的电路(比如位宽是参数)。在硬件中是没有真正“循环”的——组合逻辑电路本质上就是盒子之间的循环连接。
在硬件设计语言(比如 BlueSpec)中,所有数据结构最终都会被转换为位向量(bit vectors)。不管是整数、布尔值、颜色等等,最后统统是0和1。
循环:必须是可以在编译时完全展开的。如果循环依赖数据(动态条件),编译器会直接报错,因为硬件是静态的、不能在运行时决定循环次数。
函数调用:也不会有动态调用或堆栈,而是通过内联(inlining)——函数体在编译时直接展开,变成一块具体电路。
最终生成的硬件结构是一个无环图(DAG):节点是逻辑门、运算器,连线是信号传递,没有循环反馈。
最重要的是记住:Bluespec 的目标是描述电路,电路本质上像是画图(画出各种盒子和连线),只不过每个盒子(比如与门、或门或者更大的模块)都有具体、可定义的功能,可以用真值表来描述。这和普通画图不同,它们有确定的意义。
虽然 Bluespec 设计的首要目的是描述并综合硬件,但同样重要的是,它也能模拟电路,以验证功能正确性(functional correctness)。所以,每当你写一个 Bluespec 程序时,除了可以综合成电路,还能通过输入输出测试来验证其行为。Bluespec 存在的根本原因是为了生成电路,而不是为了计算答案。因此,Bluespec 的编译过程与传统软件语言不同。Bluespec 在编译过程中会执行大量静态展开(static elaboration):比如所有数据结构最终都会转换成位向量(bit vectors),整数、布尔值、枚举颜色等在电路中统统变成 0 和 1;
需要特别小心的是,优化器(compiler)可能会对电路做大量优化,导致生成的电路和你原本写的程序结构差异很大。比如,如果你只想让电路做“加 4”的操作,编译器可能合成出比一般加法器更小、更快的专用电路。通过 Lab 2,你会慢慢体会这种优化带来的不同。
回到 ripple-carry adder。展开(unfold)循环时,如果你设定了宽度 W,比如 2 位,就可以按照如下步骤进行静态展开:首先用 i=0 替换循环体,得到第一个 full-adder,输出 c1 和 s0;接着用 i=1 替换,第二个 full-adder 输入 c1,输出 c2 和 s1。这样,carry 位的连接关系是自动建立起来的。编译器也会确保命名的一致性,比如 c1 始终表示同一根连线。
Lec 6 时序电路
Lec 7 用接口实现时序电路模块
Lec 8 Bluespec 硬件综合
Lec 9 可编程机器
Lec 10 单周期处理器
Lec 11 多周期处理器
Lec 13 缓存
Lec 14 缓存实现
Lec 15 流水线的介绍
Lec 16 处理器流水线: 数据和控制冒险
Outline
- 回顾
- 数据冒险
- 控制冒险
- 总结
Lec 17 实现流水线:模块接口 & 并发
Lec 19 操作系统
Lec 20 虚拟内存
Lec 21 处理器流水线
Lec 22 复杂流水线和分支预测
Lec 23 旁路技术和EHR
旁路技术(bypassing, 又叫 forwarding)是一种为了减少stall,在数据的生产-消费者之间的提供额外的数据通路的技术。常规途经而言,一个值会被写回寄存器文件(register file),然后由 decode 阶段读取。而Bypassing允许值被计算出来的同时,就直接被decode阶段使用,而不等写回。
副作用:Bypassing 会引入新的组合逻辑路径,可能导致组合延迟增加,从而延长时钟周期,也会增加芯片面积。
权衡:是否启用bypassing取决于软件/程序运行时使用模式,必须通过实际综合(synthesis)去评估性能收益 vs. 成本。
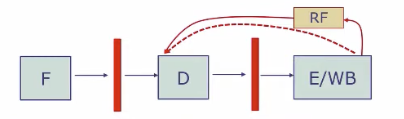
EHR(Explicitly Handled Registers)是Bluespec 中一种机制,用于精确控制寄存器的写入和读取,搭配 bypassing 使用时,可以实现更灵活的控制路径数据传递和调度。
Lec 24 并发与同步
同步(Synchronization)。我们已经学习OS通过时间片轮转让多个进程共享CPU,现在进一步,即使在单个进程内,也可以划分多个线程,现代CPU是多核的,我们系统尽可能并行执行多个线程。多线程执行一般分为独立线程,和协作线程,其中独立线程各自,除非访问共享资源,否则可并行运行;而协作线程则是共享数据,一起解决问题,必须同步通信。
Outline
- 同步场景 & 模式
- 引例:有界缓冲区问题
- 信号量
- 死锁问题
Lec 25 缓存一致性
缓存一致性(Cache coherence),在现代微处理器中,往往会有多个核心,每个核心都有一个私有缓存(以提高加载/存储性能),但是,主存是所有核心共享的。因此核心经常通过与主内存的交互来进行通信。因此,我们需要确保操作看起来像是在一个共享内存上进行。
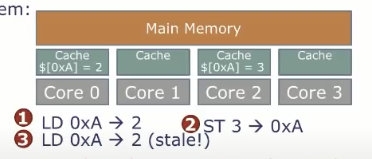
问题出现在,如下示例。0号核心通过加载指令获取0xA地址上的值为2,接着2号核心向0xA地址设置值为3,此时0号核心上私有缓存的0xA的值是过时的。 解决办法就是,通过一个缓存一致性协议来控制缓存的内容,避免出现过期缓存行,比如,核心2在写入3之前将核心0的副本无效化(invalidate)。
Outline
- 缓存一致性协议
- 基于监听的缓存一致性
- 基于目录的缓存一致性
- 缓存一致性的实践经验